Algolia search is good. So good, that many open source projects have moved to its free DocSearch project. When you search VuePress documentation you are using Algolia's backend, same with Yarn docs, same with Babel docs, and many others.
Great, let's see how we can take a static site like https://glebbahmutov.com/triple-tested/ and create an Algolia index for it, then scrape the site's contents. Then we will add a search to the static site powered by Algolia's index.
Set up Algolia app
First, I created a new Algolia account and have created a new application to host my experiment.
Pro tip: rename your application to something meaningful from https://www.algolia.com/account/applications page after creating it.
Then set up a new index inside the application. For this blog post I called the index scrape-test, the screenshot below shows the index after I have added a few records there.
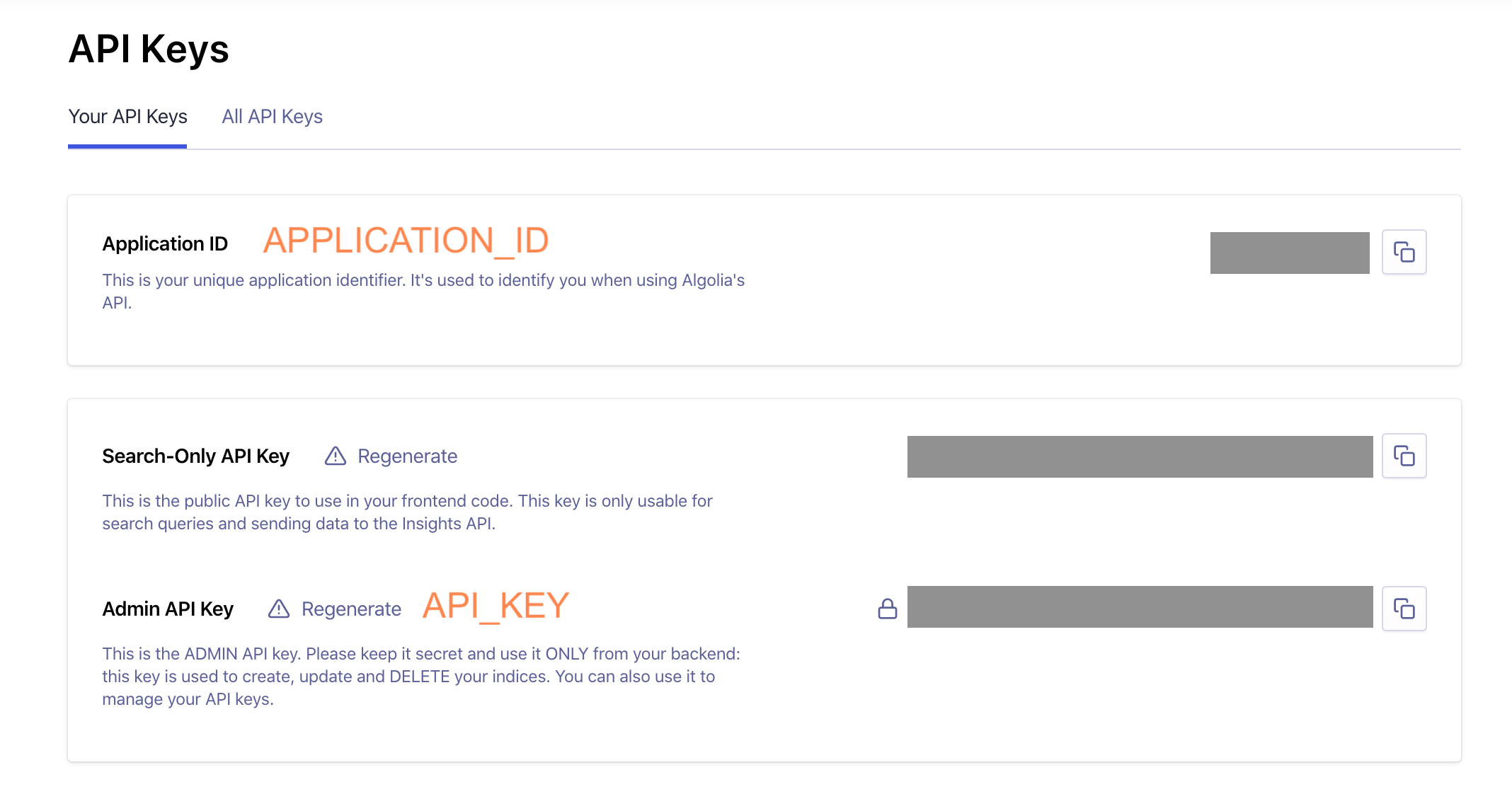
To scrape any site and send results to the index we need the application's ID and Admin Key. I have tried creating a separate key following Run Your Own Scraper documentation, but I was always getting "Index not allowed with this API key" error. So just grab the Admin Key (but keep it really secret).
Scraping the site
I have created a repo bahmutov/scrape-test to show scraping in action. First, we need to think what is important on the page, and the hierarchy of results. For example, text matching <h1> element is probably more important than text matching <h3>. In demo I will be scraping a VuePress site from bahmutov/triple-tested which is a VuePress site. I can look at VuePress Algolia scrape config file to see how they set it up.
1 | { |
The last selector text requires explanation. Algolia's docs suggest splitting long text blocks into individual short records, see 1, 2. We can check the text selector from DevTools console to see the short records it finds.
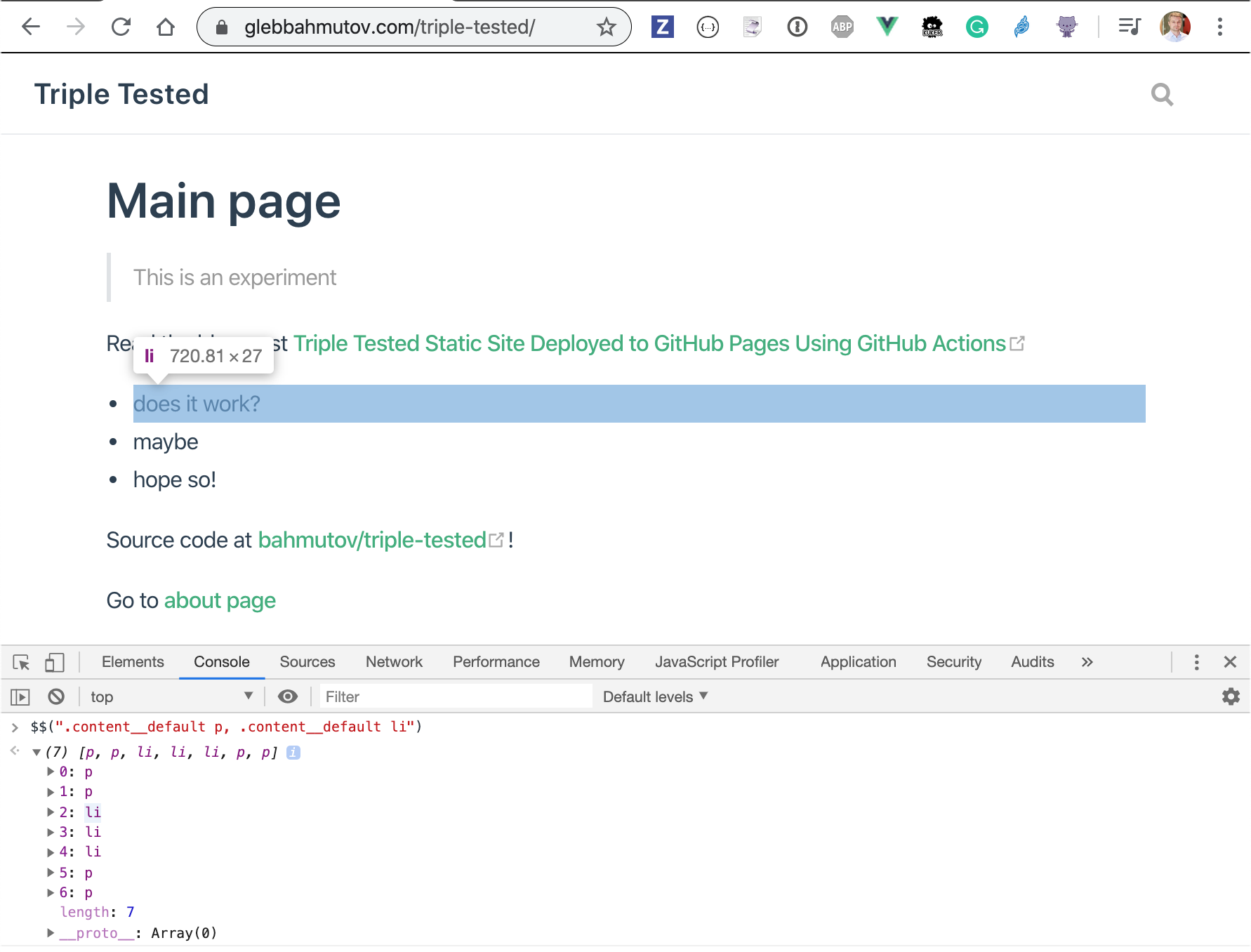
Let's scrape the site. The simplest way is to use Algolia-provided Docker image. Here is how I run it from the root of the scrape-test repo (where config.json file lives).
I place APPLICATION_ID and API_KEY values into ~/.as-a/.as-a.ini file under its own section.
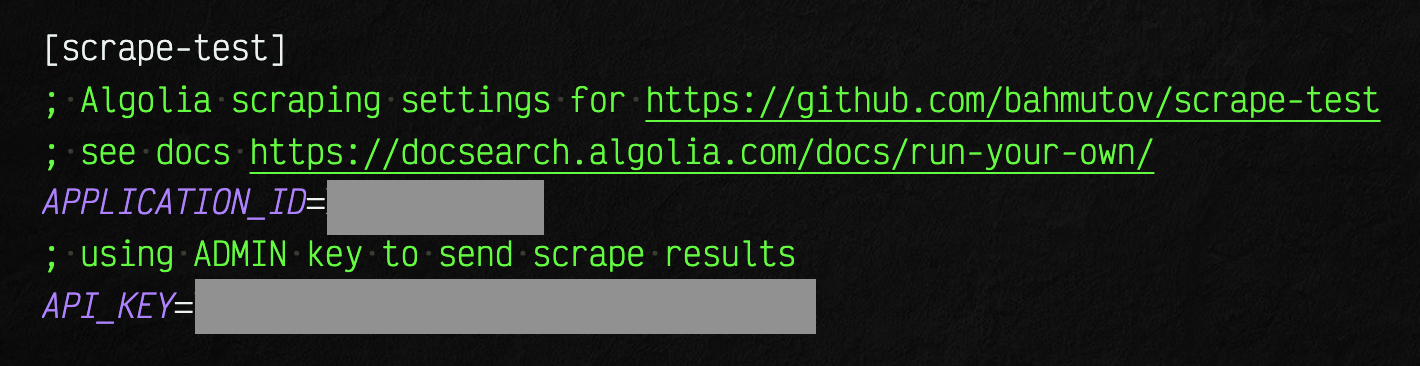
docker pull algolia/docsearch-scraper:v1.6.0
Now I will start Docker and will use as-a to run the algolia/docsearch-scraper image. I will pass keys as environment variables, and the config file too.
1 | as-a scrape-test docker run -it \ |
The scraper went like a spider through all (two) pages and found records to upload to the search index. Now let's go back to Algolia's Dashboard to check what it finds.
Scraping from the image
As a side note, we can scrape the site from inside the algolia/docsearch-scraper:v1.6.0 Docker image without executing its default entrypoint. We can inspect how the Docker image is built at docsearch-scraper. Here is the relevant line from its Dockerfile
1 | ENTRYPOINT ["pipenv", "run", "python", "-m", "src.index"] |
Let's see - let's run the same scrape job, but instead we will start the shell. Once the Docker container starts, we will enter pipenv ... command to run the scraper.
1 | $ as-a scrape-test docker run -it \ |
Great, works the same way.
Scraping from GitHub Action
Tip: if you have never used GitHub Actions, read Trying GitHub Actions blog post
We don't want to scrape the site from local machine, let's do it from Continuous Integration (CI) server. Since the repository is already on GitHub, let's use GH Actions. Let's create workflow file .github/workflows/scrape.yml.
1 | name: scrape |
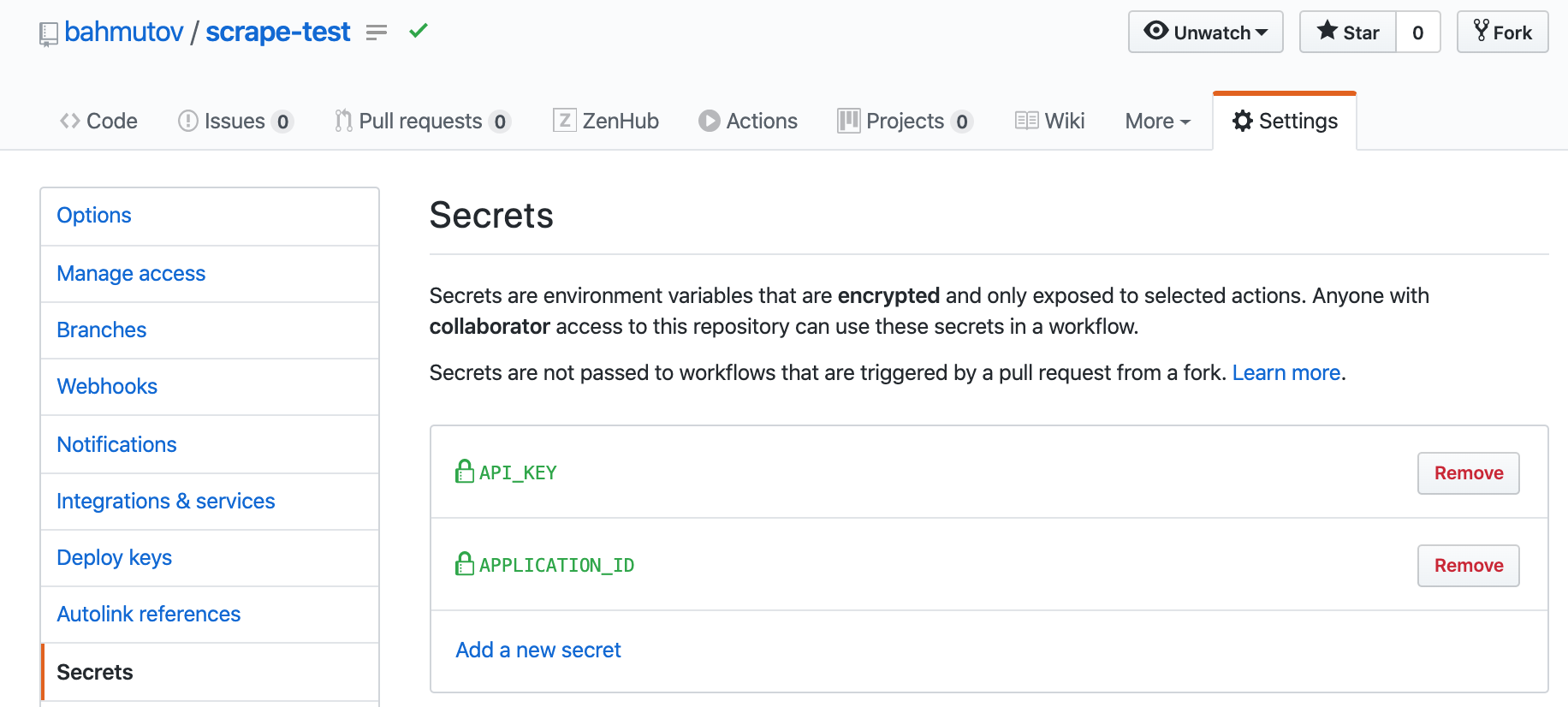
Enter the application id and API key in repository's secrets.
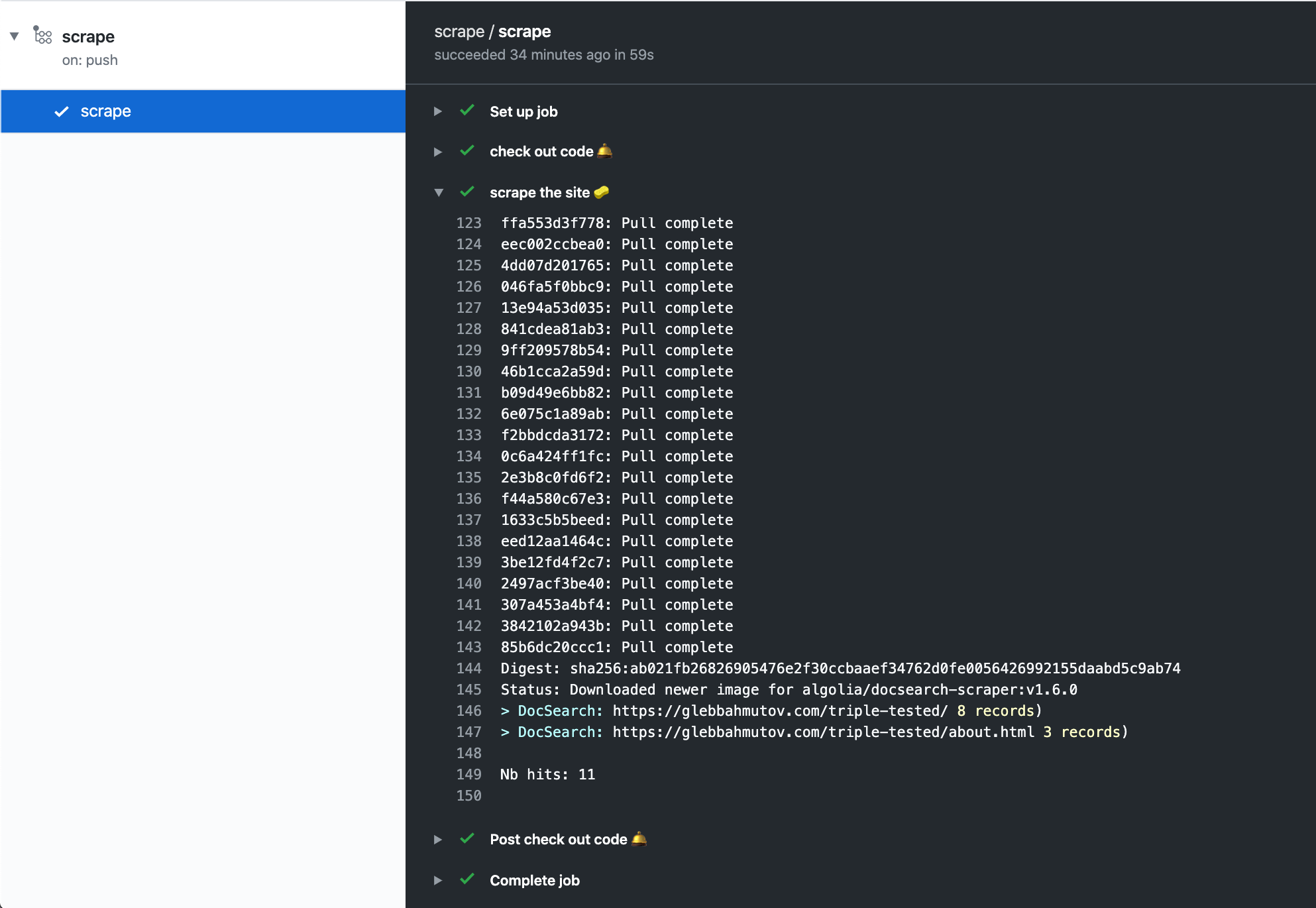
Push the code and see Actions run.
Tip: if you are deploying the site to GitHub Pages, you could run the scraper AFTER deploy finishes, read Triple Tested Static Site Deployed to GitHub Pages Using GitHub Actions
Adding the Algolia search widget
We have populated the search index, now let's switch our demo site from built-in client-side search to Algolia's search widget. You can see the VuePress site in bahmutov/triple-tested repository.
I have updated the docs/.vuepress/config.js to include Algolia settings.
1 | module.exports = { |
This apiKey is NOT the Admin API key we have used to scrape the site, this is a key limited to searching the index only.
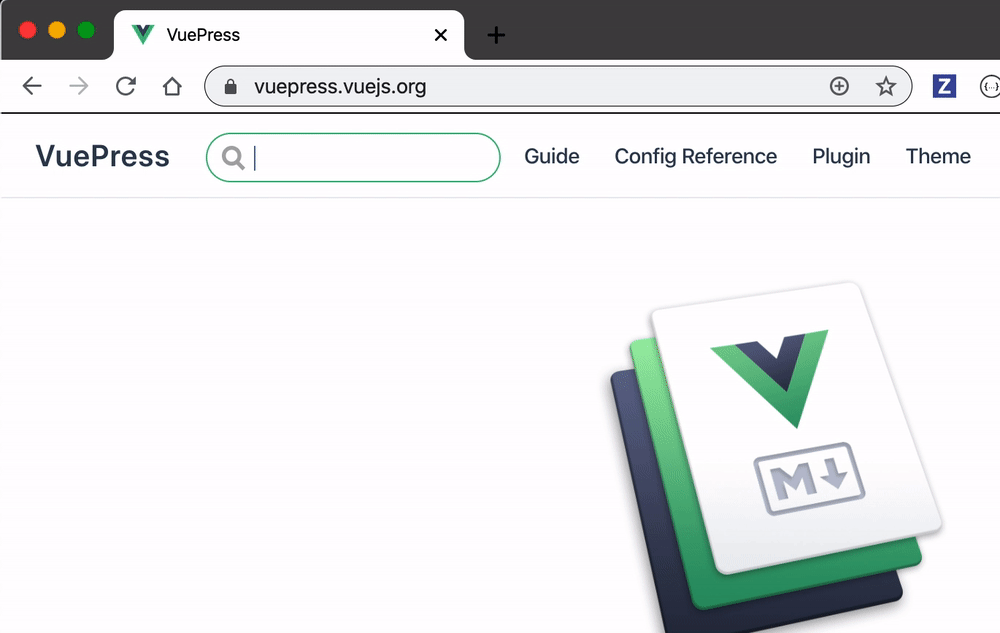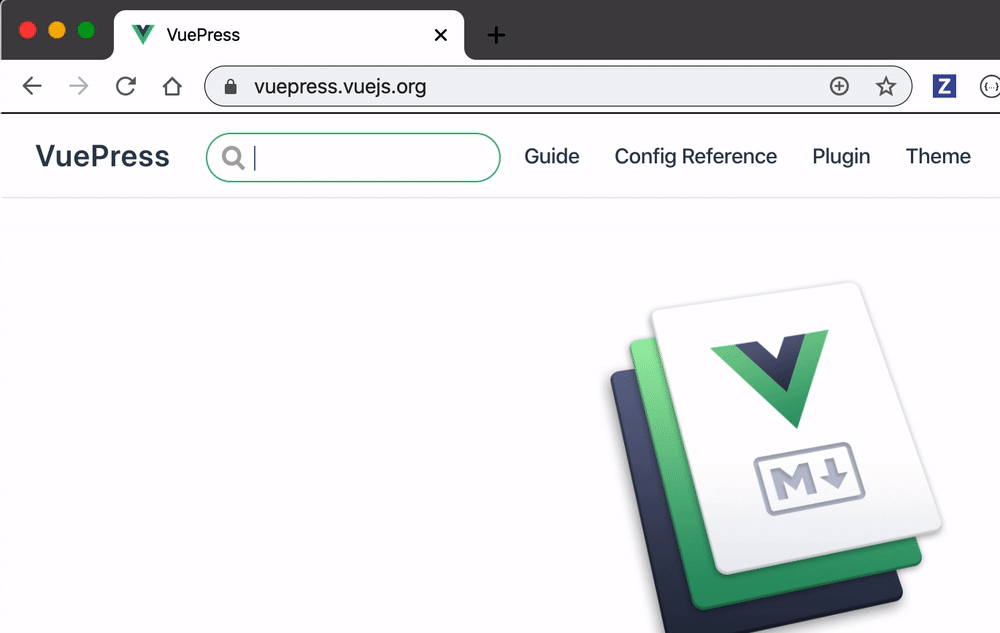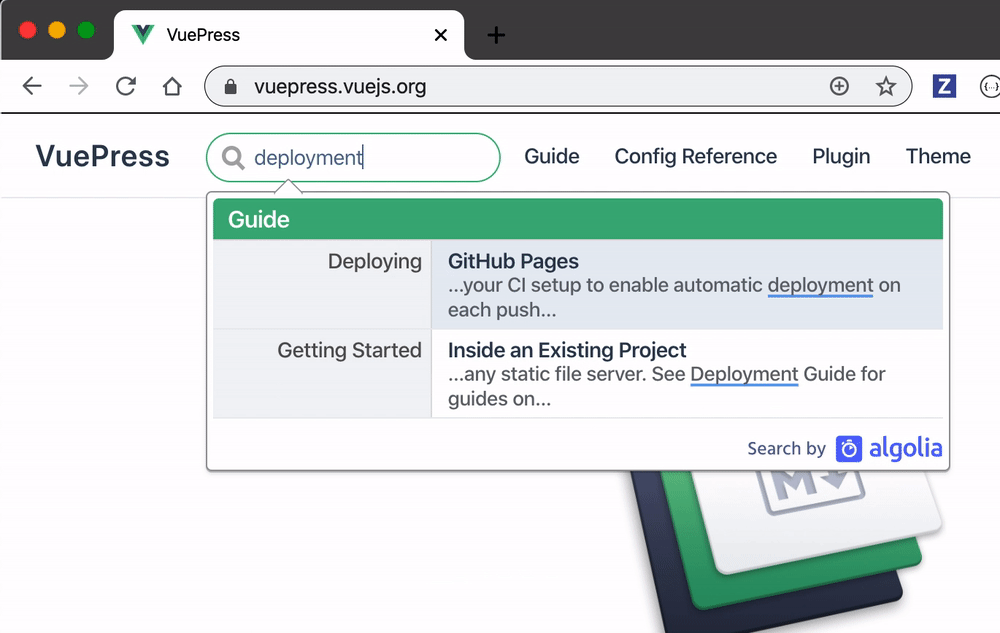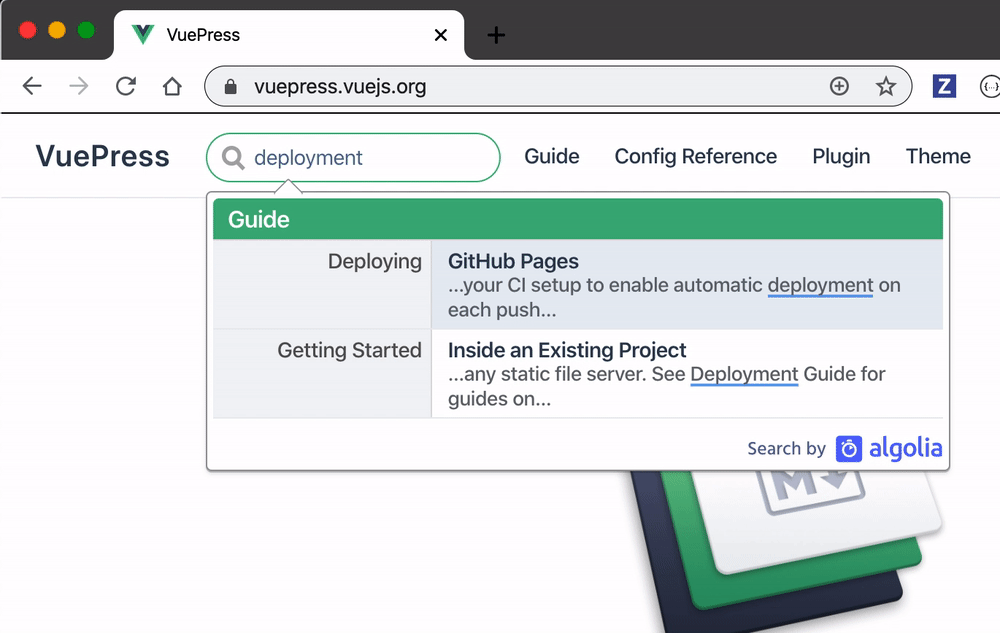
Once the site starts, try the search ... and you won't see any results 😟
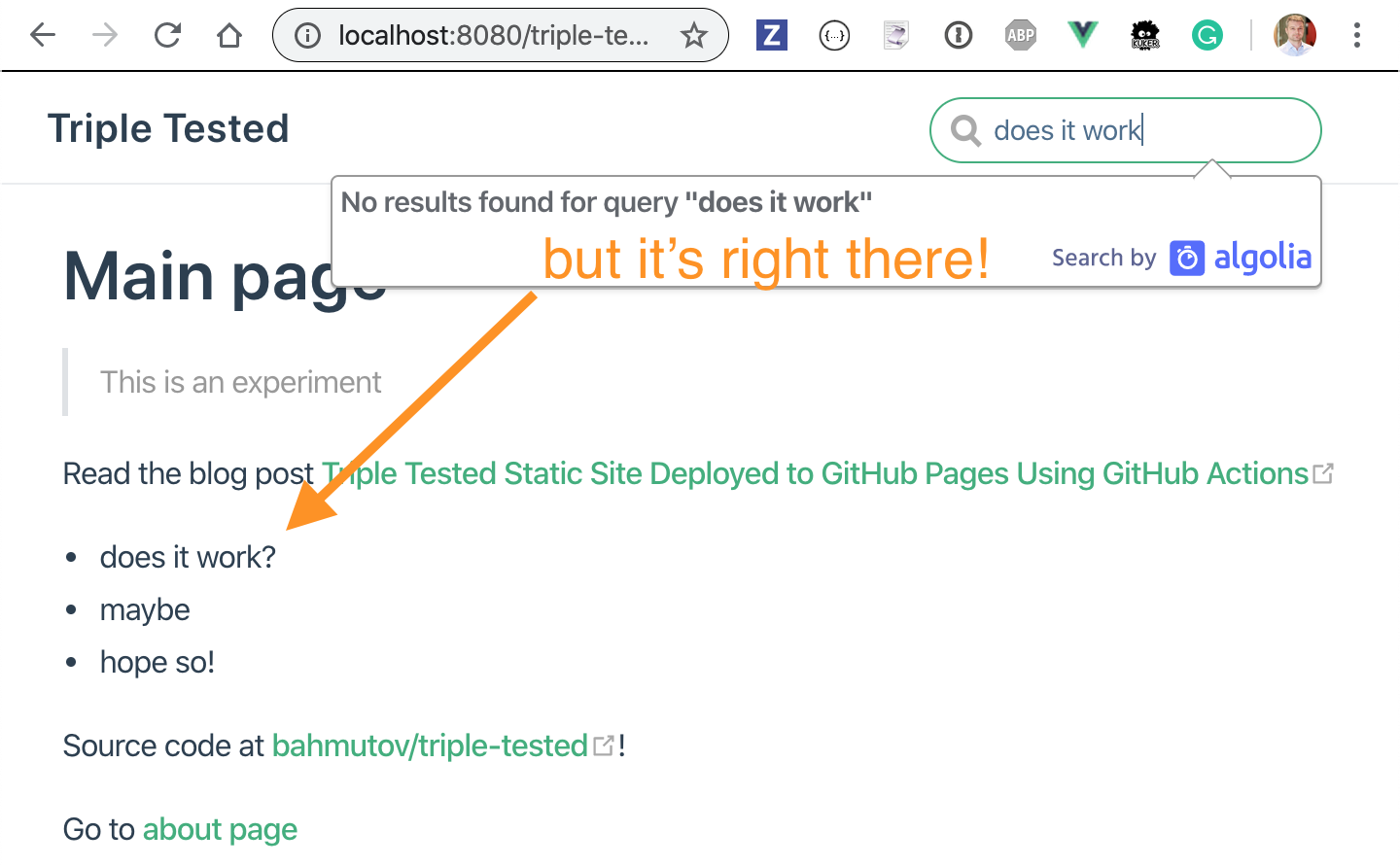
Open DevTools Network panel to see the queries from Algolia's search box - notice they include a facet lang: en-US.
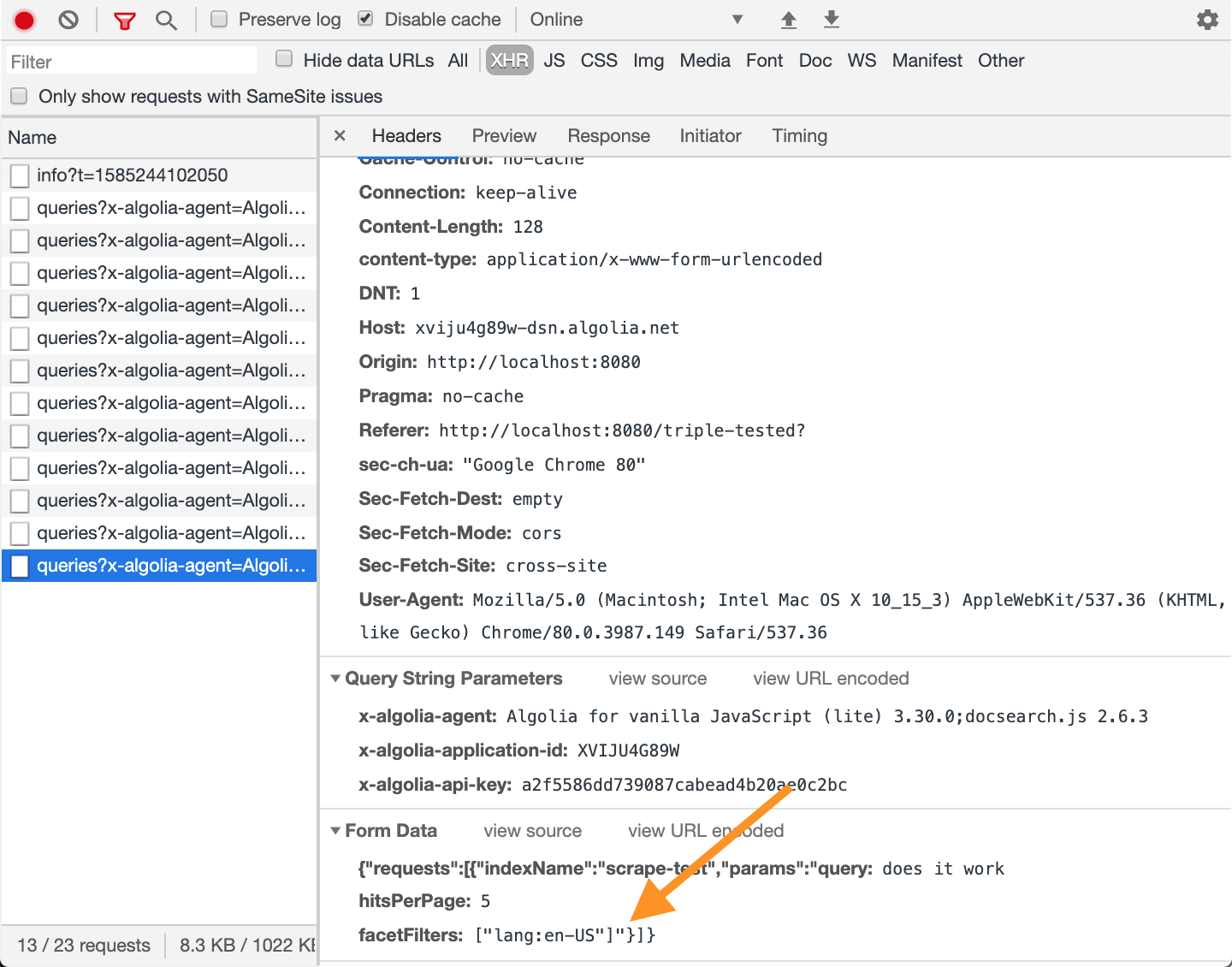
Our Algolia application does not know the language of each record in the index. Thus we need to go back to DocSearch VuePress config file to see how they have set it up. Among selectors we can find the following:
1 | { |
Great - the lang selector tells the scraper to use <html lang="en"> attribute. Let's copy the above settings and scrape again. Now each record has additional facet attribute, and testing the index correctly finds the record and shows the language facet.
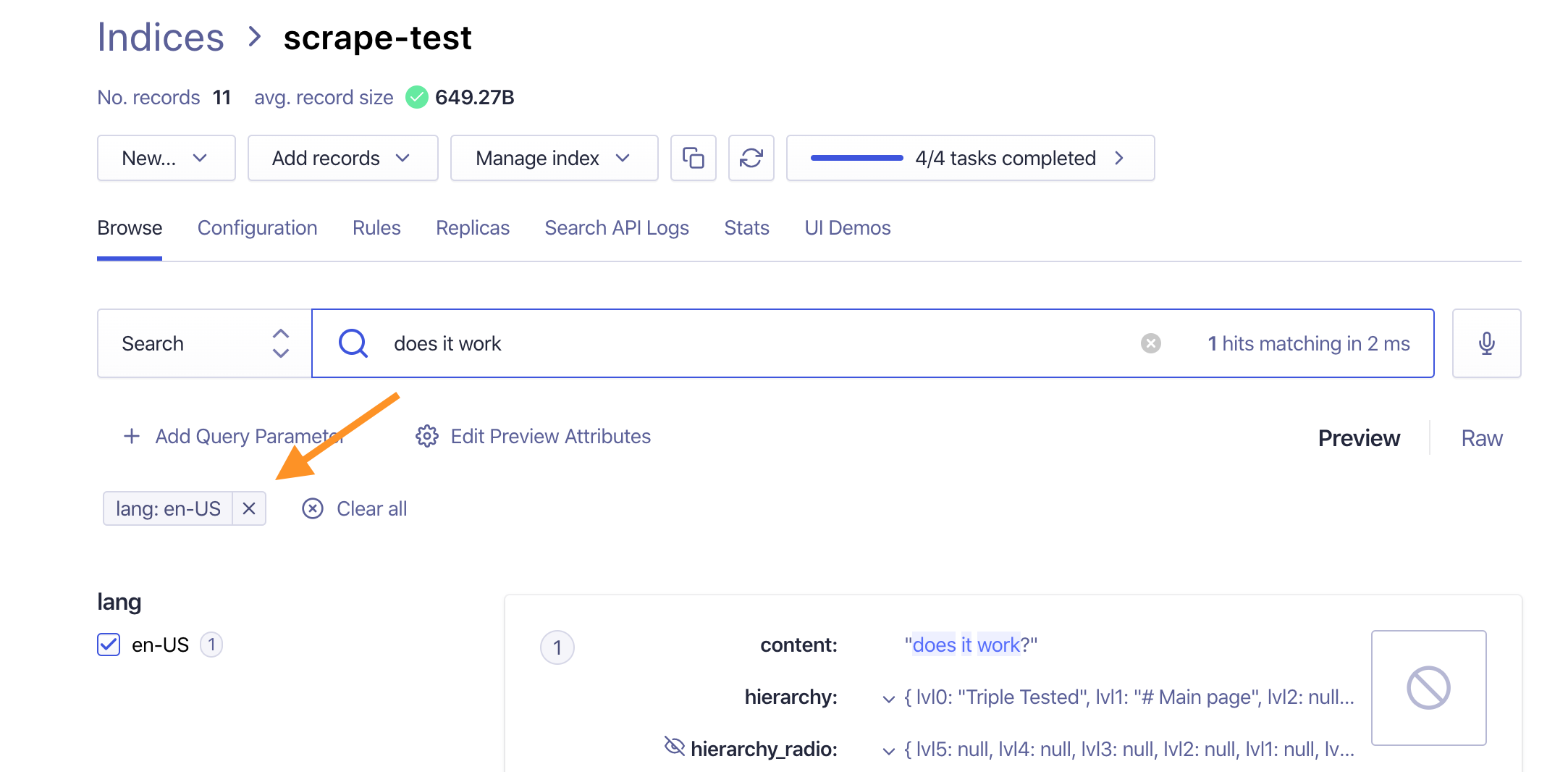
Going back to the widget - it is working now!
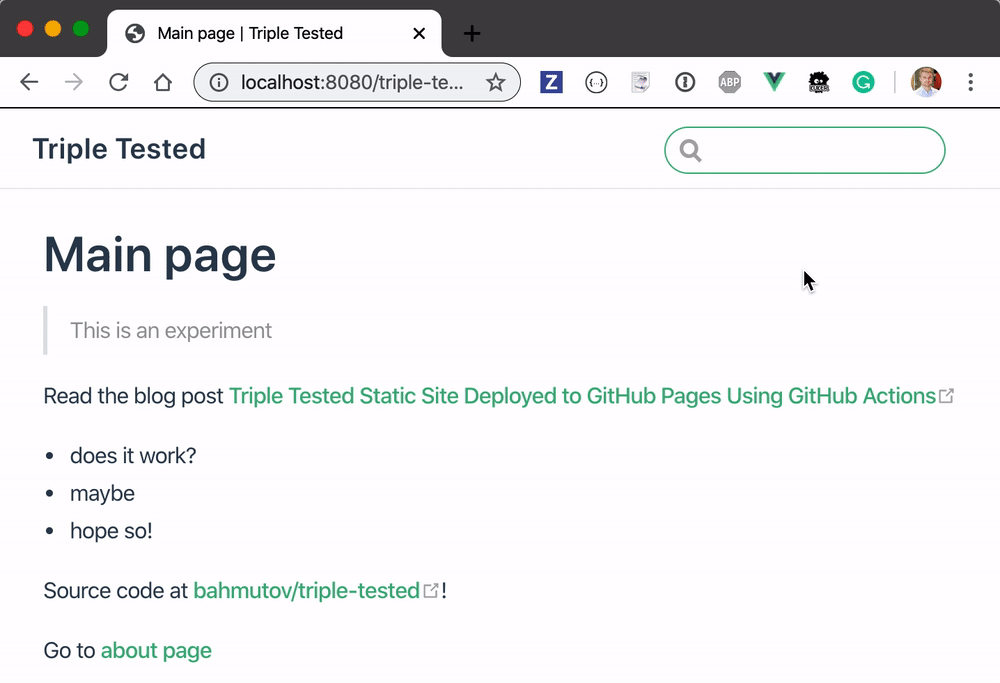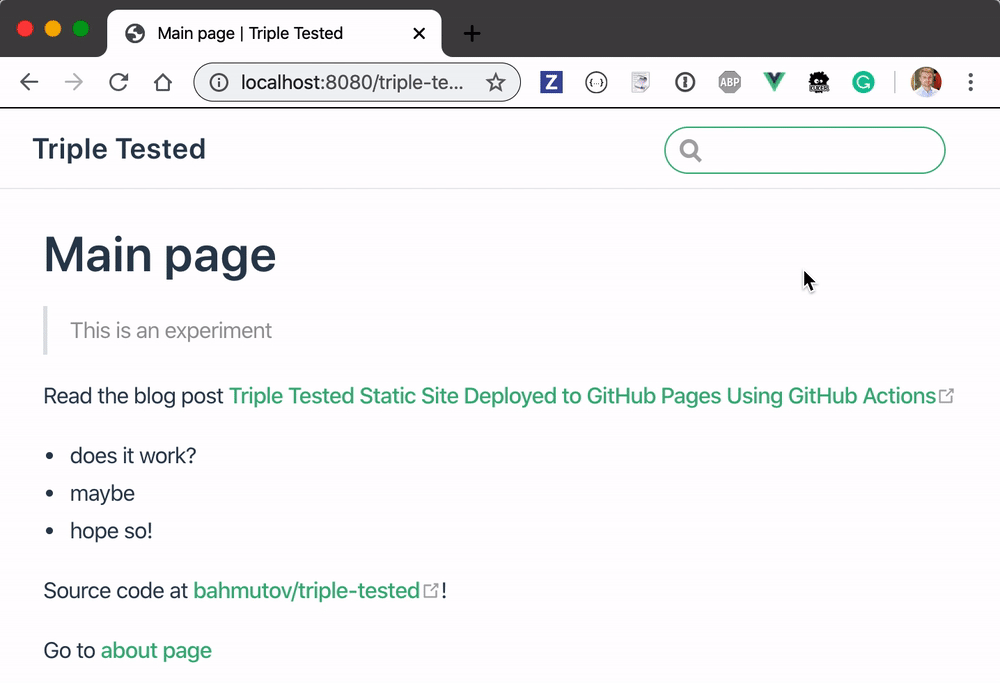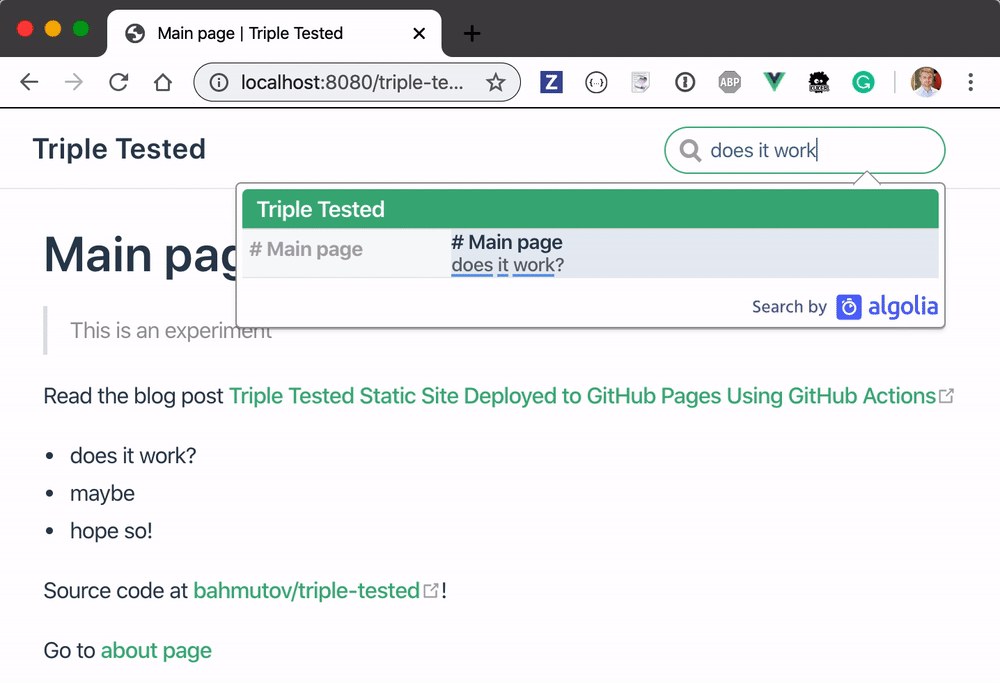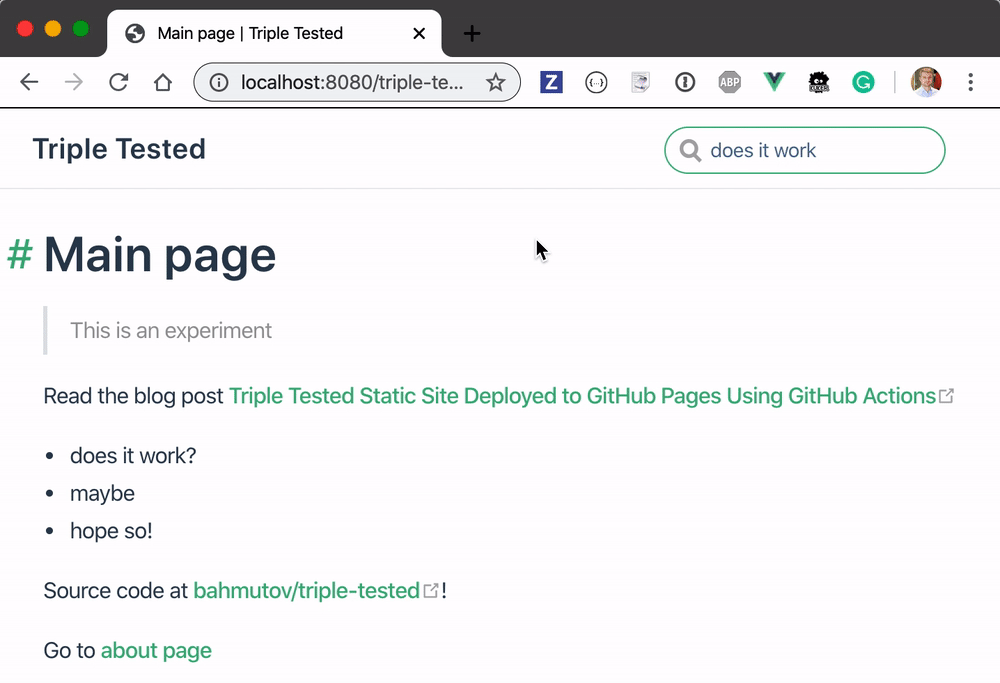
You can try the search yourself at https://glebbahmutov.com/triple-tested/.
Example repos
Update 1: have lvl0
I have noticed the Algolia DocSearch widget breaking if the scraped records do not have "lvl0" in their hierarchy. Make sure the config file uses the title for example:
1 | { |
Check the scraped records to make sure "lvl0" is set.