When running Cypress tests in parallel you might notice a curious thing: some of the machines are late to the party!
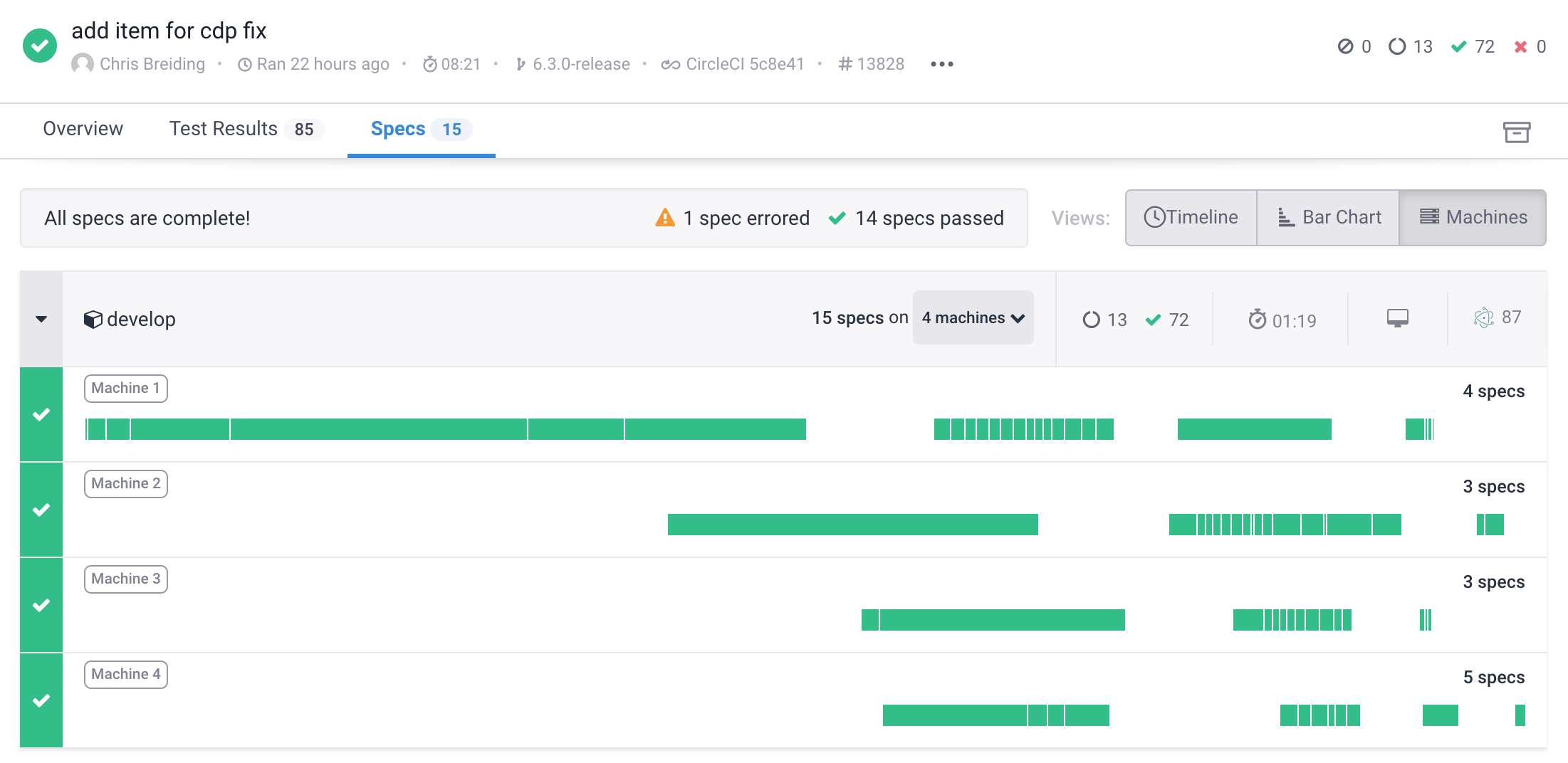
The above difference is significant - the first machine goes through the longest spec by the time the other three machines start executing the other specs. The above test run takes longer than necessary, just because the machines are not splitting the load equally. Why is this happening?
We are running the tests on CircleCI using Cypress Orb. Our job definition is identical for all four machines: we simply say that we want 4 parallel containers:
1 | version: 2.1 |
Let's look at the timings reported by Circle for each of the four containers. Every container prepares the Docker cypress/base image, attaches the workspace with source and dependencies, and then runs the tests. The video below shows the time durations between the machines:
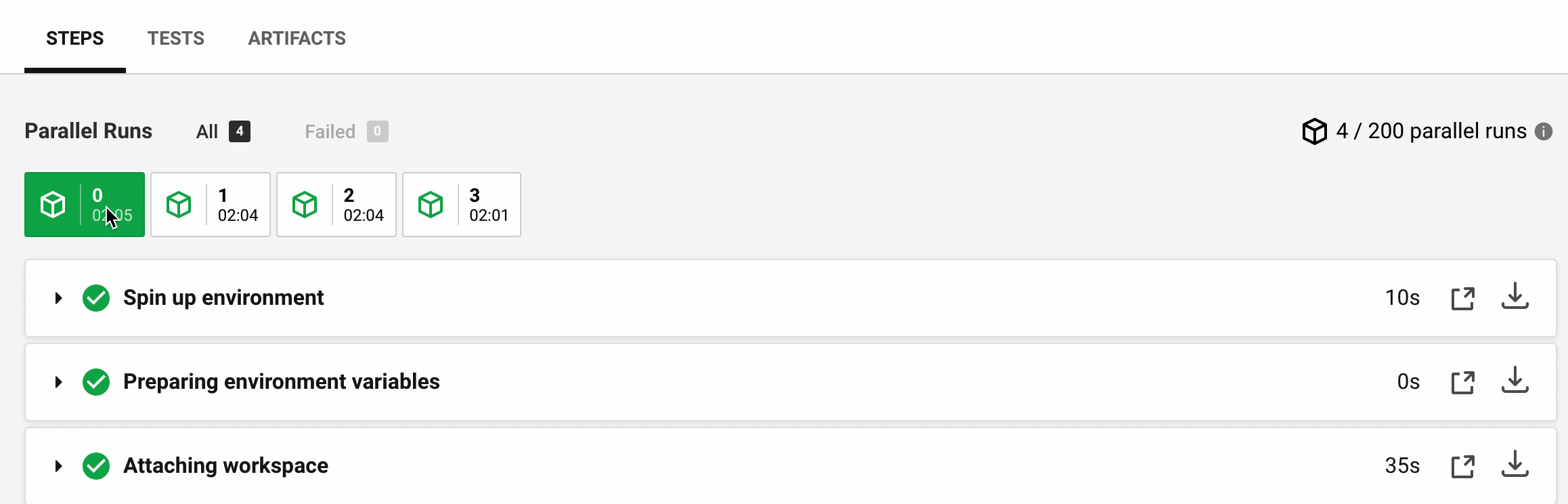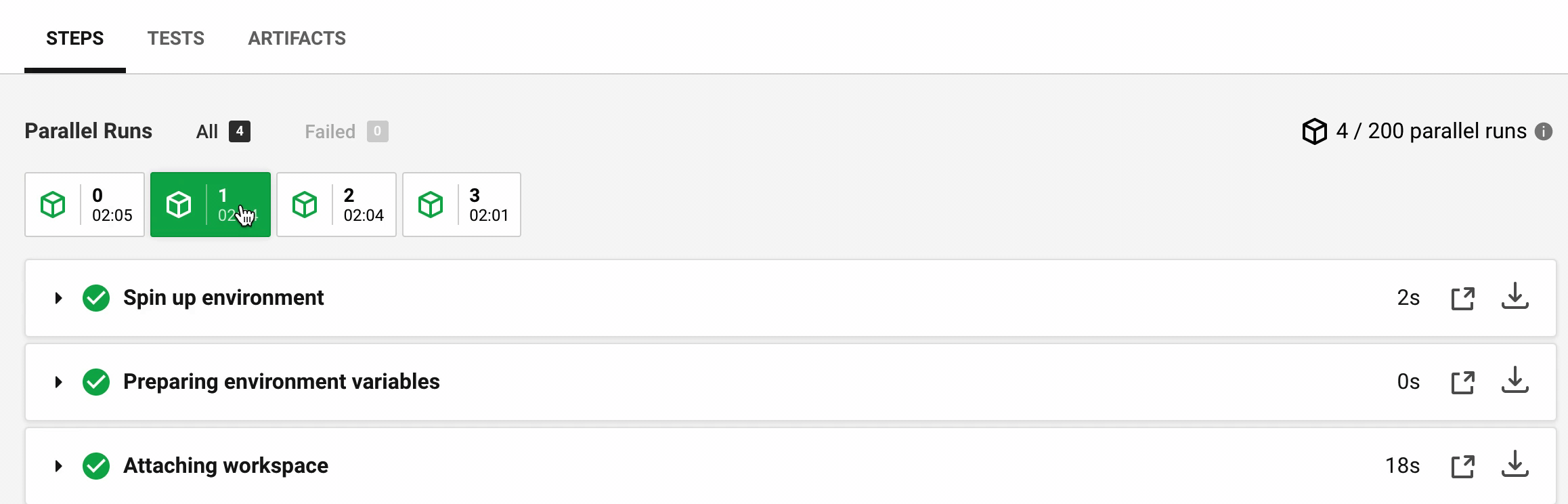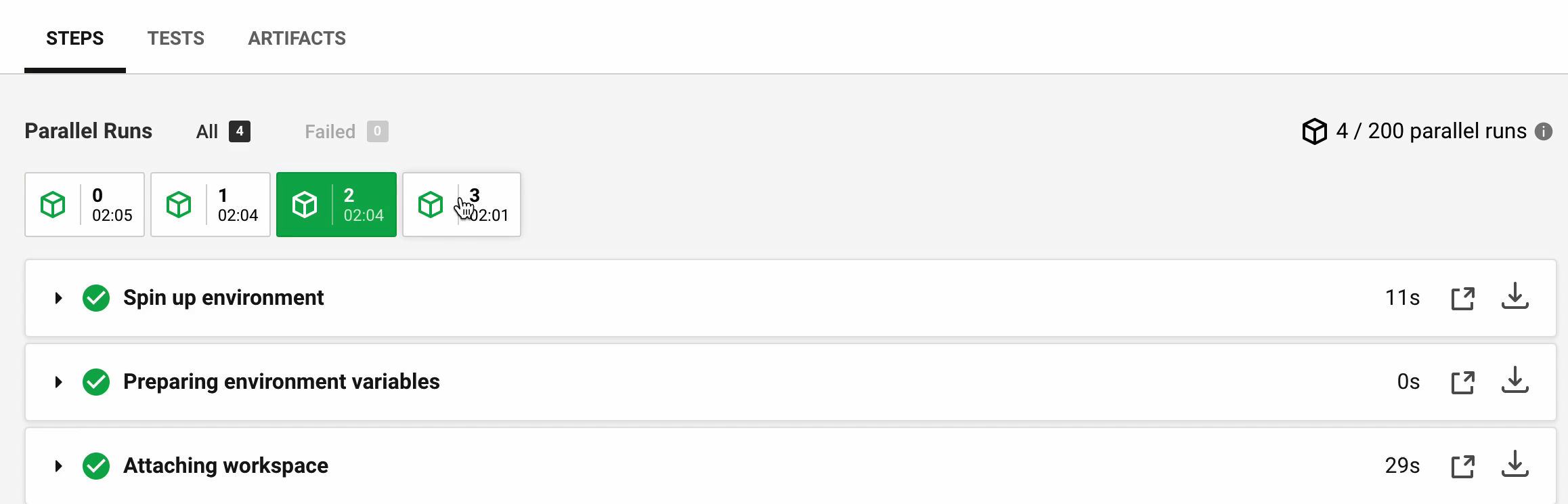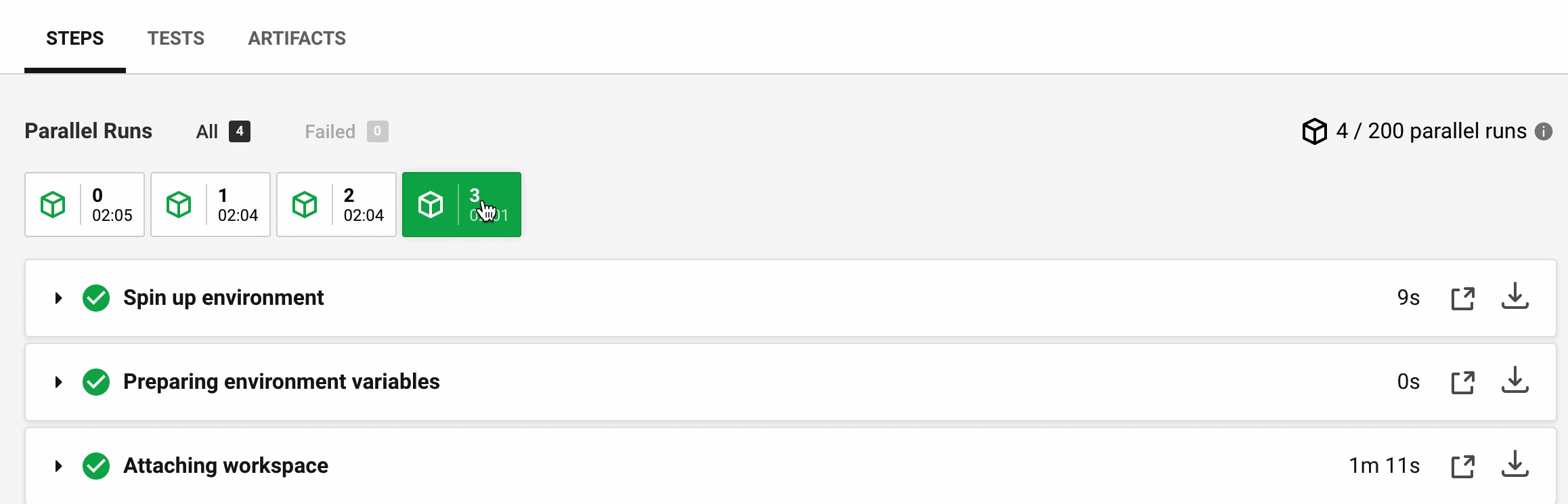
The time it takes for CircleCI to prepare a Docker image and attach the workspace folder can vary significantly. For this example (which comes from cypress-documentation) the times in seconds were:
Step | M0 | M1 | M2 | M3 --- | --- | --- | --- Spin up | 10 | 2 | 11 | 9 Attaching workspace | 35 | 18 | 29 | 71
Hmm, that's very different - no wonder the machine M1 started testing the spec 60 seconds before the machine M3 joined the run. The above variance is not a fluke. Here are the same timings from cypress-realworld-app test execution.
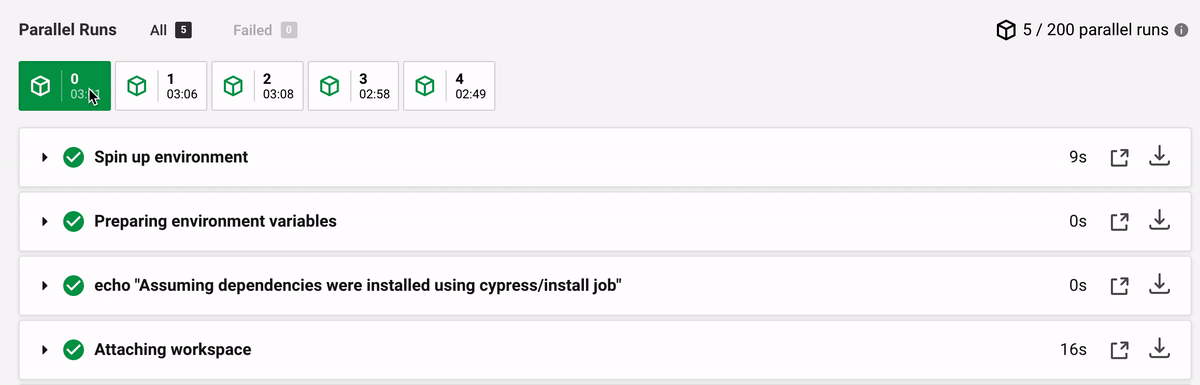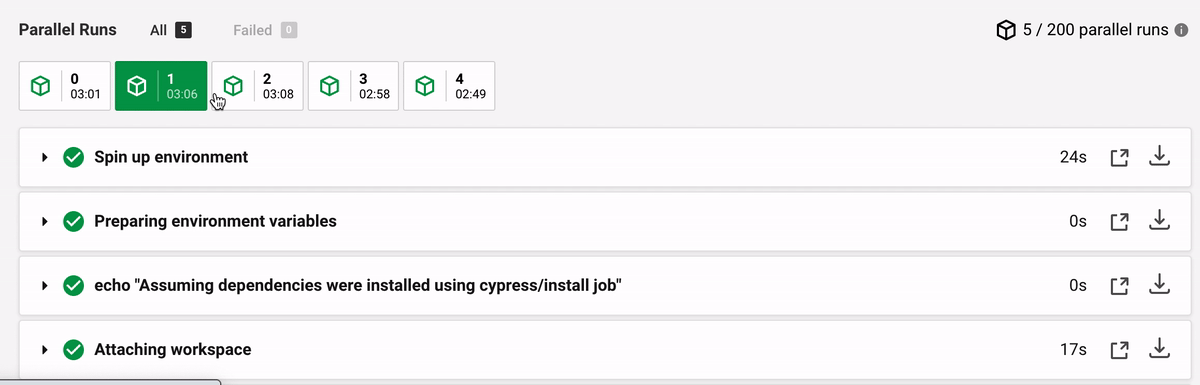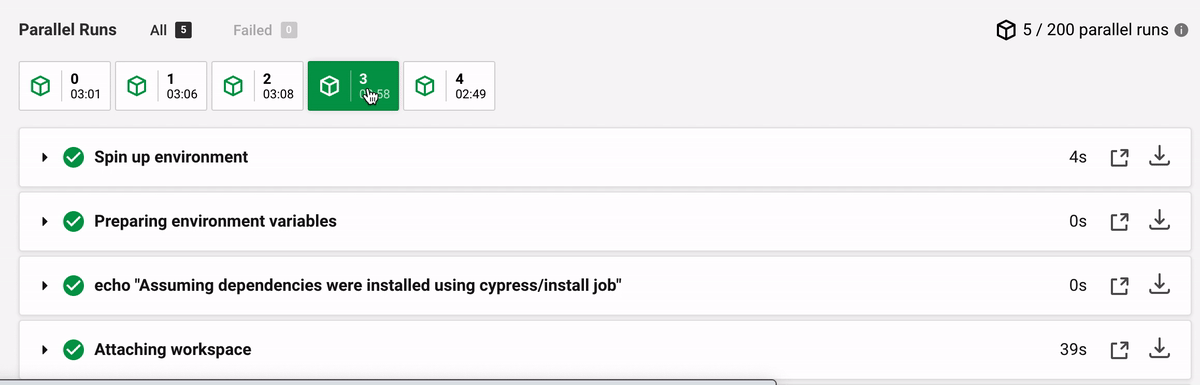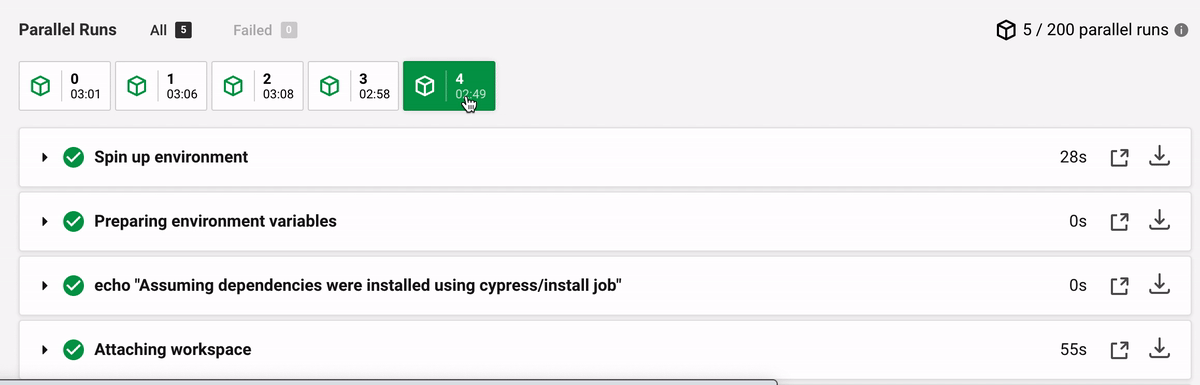
The time differences between the machines are extreme (in seconds):
Step | M0 | M1 | M2 | M3 | M4 --- | --- | --- | --- | --- Spin up | 9 | 24 | 3 | 4 | 28 Attaching workspace | 16 | 17 | 111 | 39 | 55
What can we do to prepare the machines and start the tests at the same time?
I have asked the CircleCI support forum about this difference. They have blamed it on the CI machines being IO-bound. Meaning the start of the container is very disk-heavy - you are downloading a Docker image, then downloading the workspace archive and copying it to the container. If multiple CI containers all copy lots of files, then the IO system gets full and some machines have to wait their turn, delaying the above steps.
The possible solution is to use the CircleCI RAM disk. It is a special folder that is located not on disk, but entirely on memory. Since even the medium CircleCI machines have plenty of memory, if our Node process needs < 1GB of disk, then it can fit in memory! We are still downloading the Docker image via network, but it should be much less intensive process than downloading and writing it on disk (together with the workspace).
To use the RAM disk, you just set the working directory to /mnt/ram-disk like this:
1 | working_directory: /mnt/ramdisk |
Of course, in case of Cypress we also want to store the NPM folder and Cypress binary folder on the same disk. To control the Cypress binary cache folder we can use the environment variable CYPRESS_CACHE_FOLDER. We can change the NPM global cache module path using the npm config --global set cache command. Thus the full workflow with a separate single install job and parallel test jobs would be something like this:
1 | version: 2.1 |
🎁 You can find the full source code in the repo cypress-io/testing-workshop-cypress and its file .circleci/config.yml.
The entire work is done using the RAM disk. Let's see the new timings for Cypress documentation project:
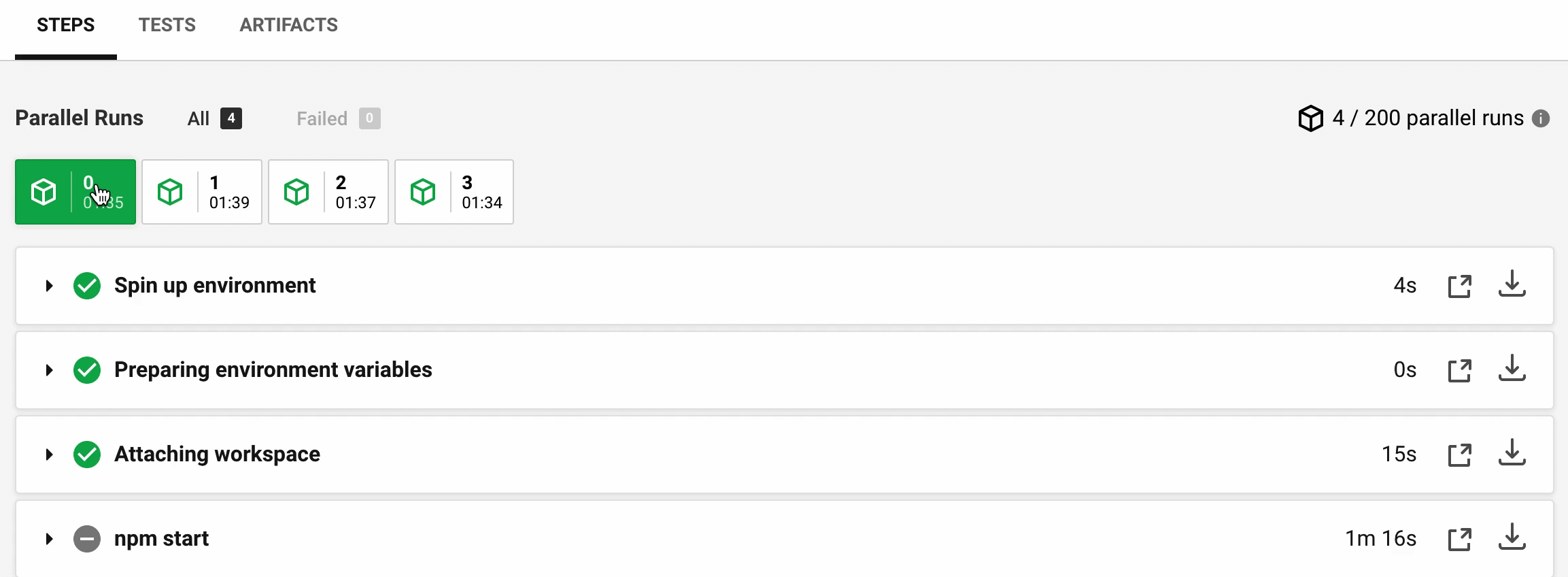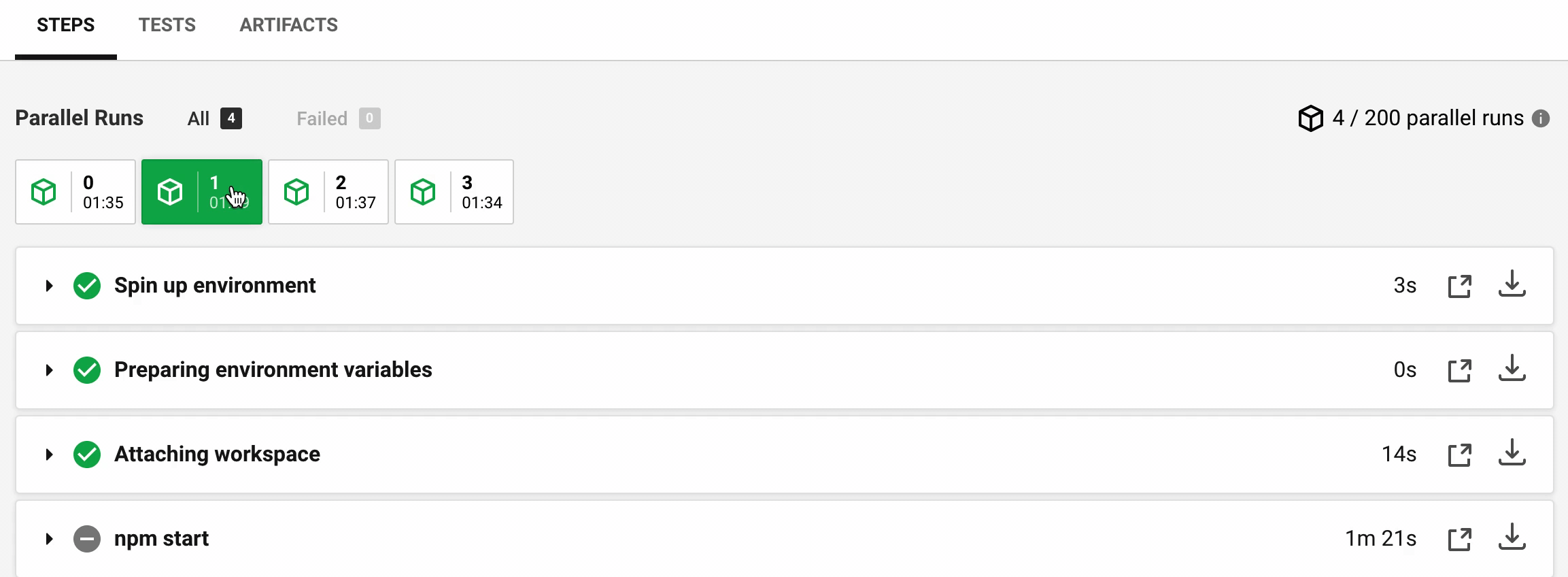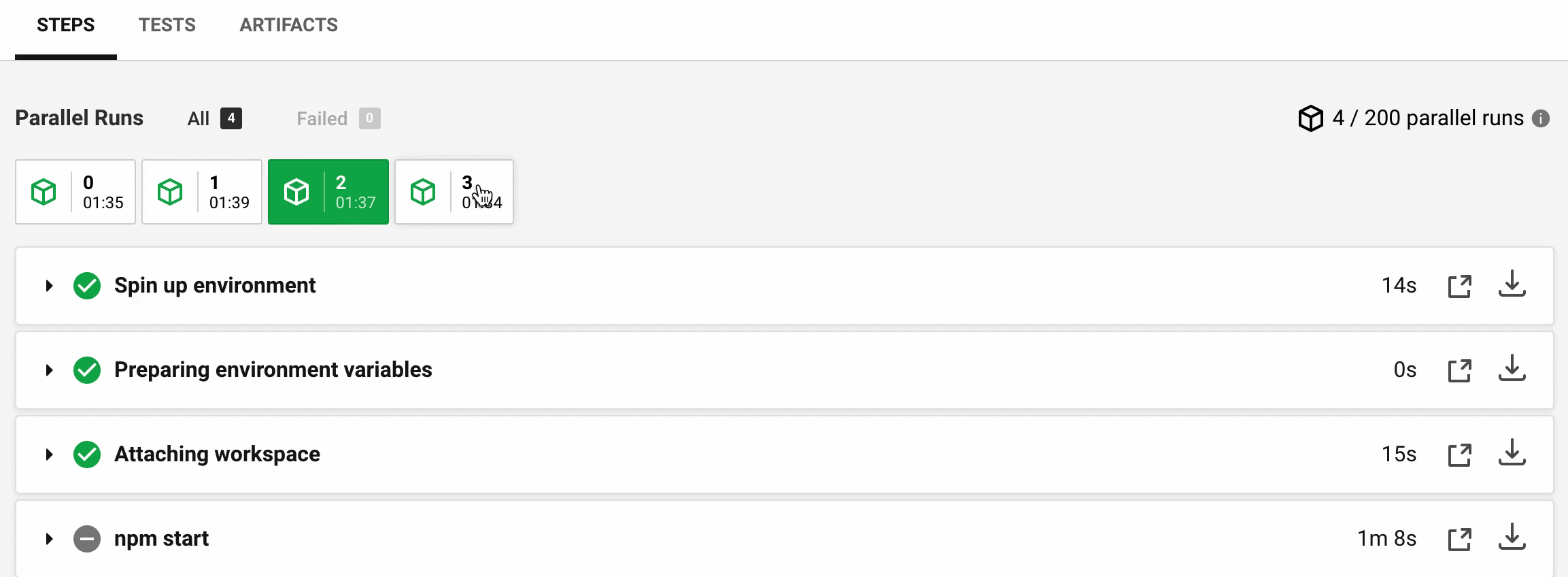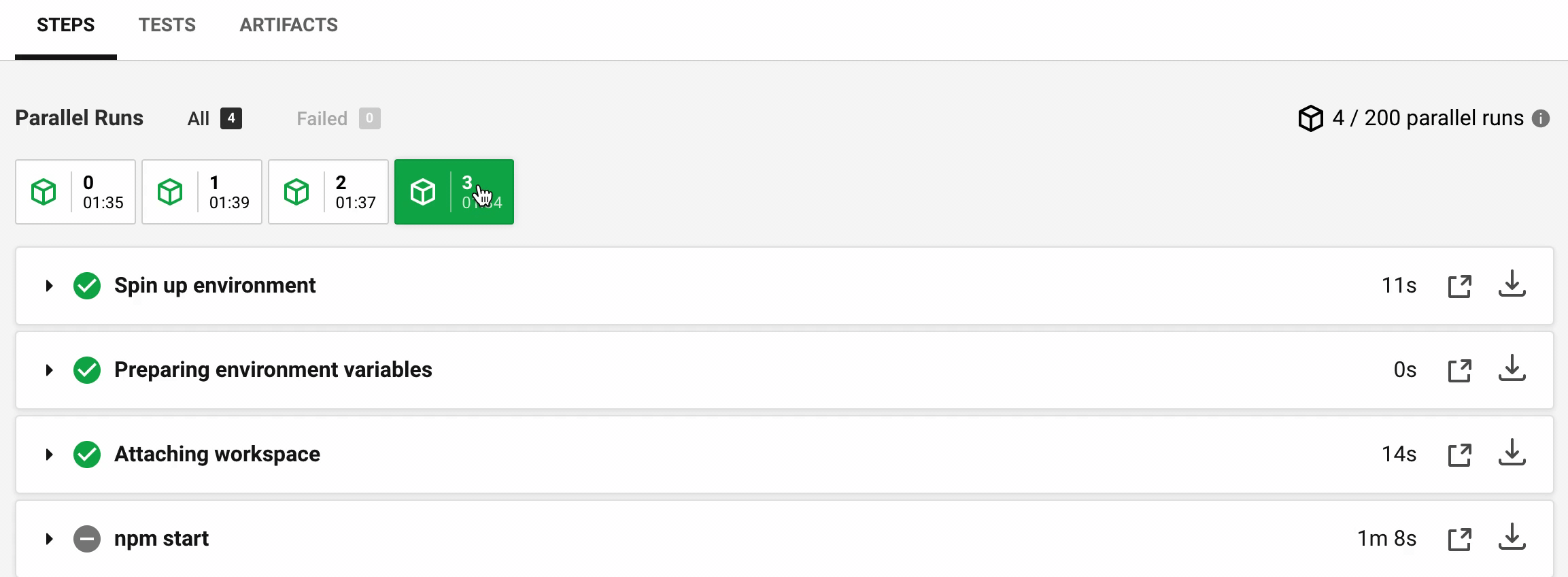
The timings are much more consistent now (in seconds):
Step | M0 | M1 | M2 | M3 --- | --- | --- | --- Spin up | 4 | 3 | 14 | 11 Attaching workspace | 15 | 14 | 15 | 14
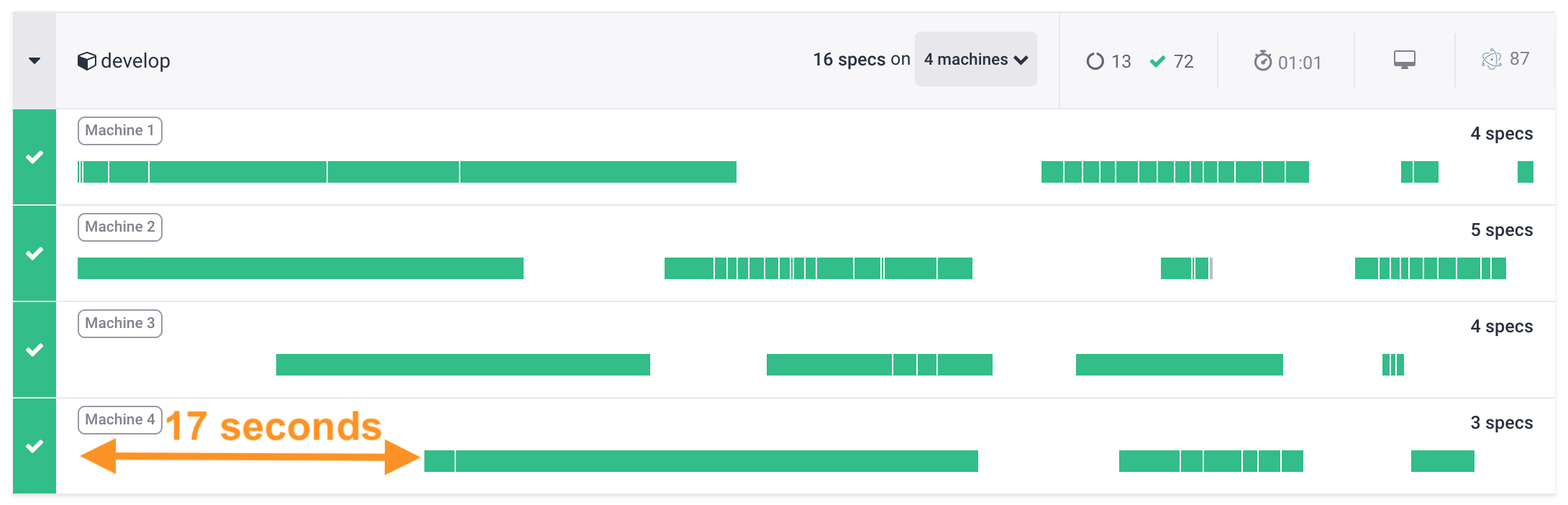
The specs are now much more uniform and start approximately at the same time. The latest machine 4 has joined the run only 17 seconds after the first machine.
⚠️ The RAM disk approach is not yet compatible with Cypress CircleCI Orb because of the assumptions the orb makes about the folders. Follow issue #325 to find when we make the orb faster by allowing to use the RAM disk.