Sometimes you want to simply visit every local page on your site to make sure the links are correct and every page loads. Cypress is not a crawler, but it can definitely handle the crawl for smaller sites. In the videos below I show how to collect every anchor link, filter external links, and visit every collected URL once.
🎁 You can find the full source code in my repository bahmutov/cypress-crawl-example.
Collect the URLs
The best way to write a crawler is to think about the actions on every page. The crawler needs to:
- grab the first URL to visit from a queue
- if there are no URLs to visit, we are done
- call
cy.visit(url) - collect all anchor elements
- filter external links
- filter links we have already visited
- filter links we have already queued up to visit
- add the filtered URLs to the queue
- go to step 1
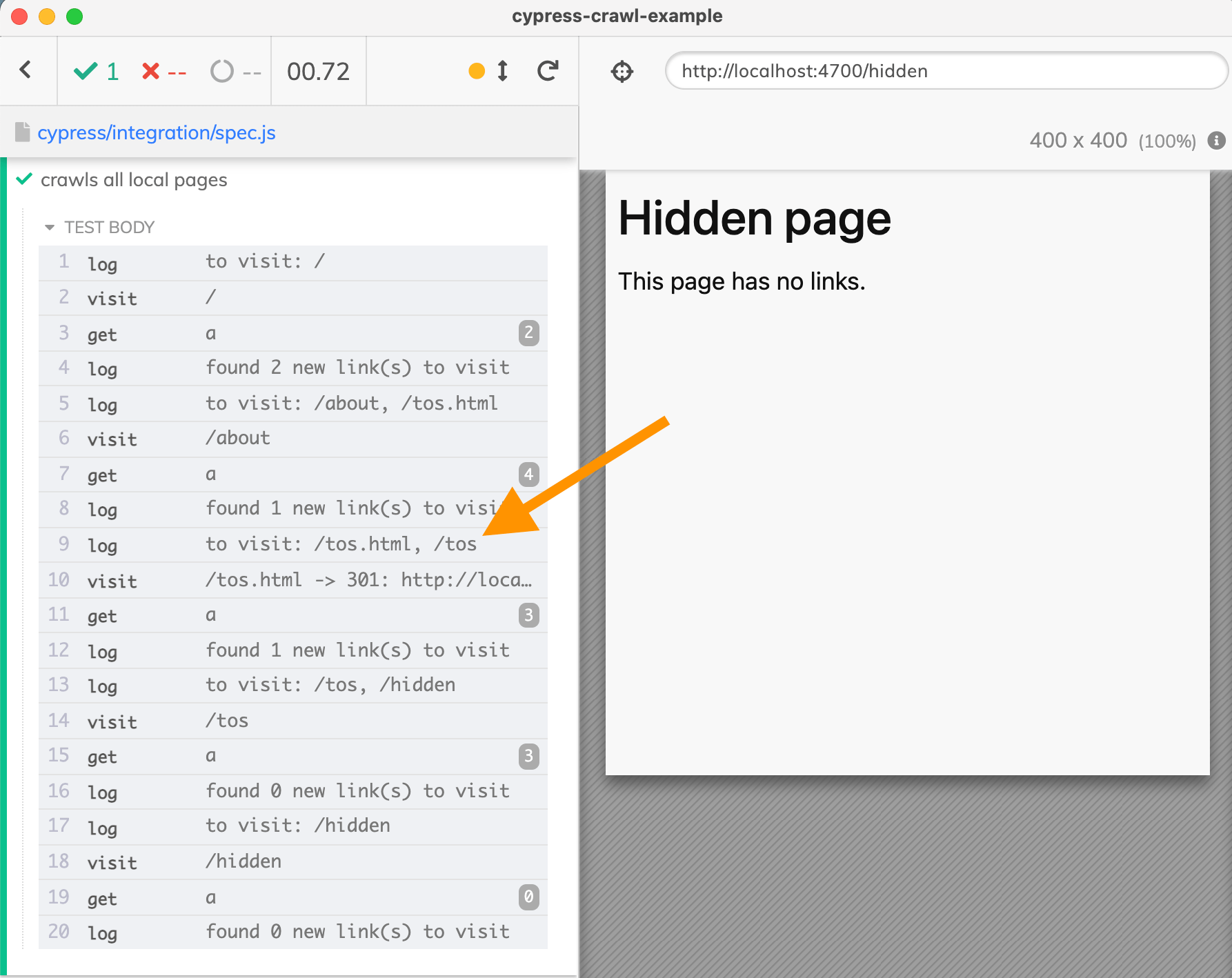
You can see my implementation of the above steps in the test file spec.js and watch the implementation in the video below:
Perfect, at the end of the test each URL has been visited, but some pages were visited twice - because the crawler does not know that links to /tos.html and /tos lead to the same page.
Resolving URLs
To prevent visiting the same page via different links, we need to check if a given URL leads to a page we have visited already. We can do this by using the cy.request command and inspecting the redirects array.
1 | // check URLs by requesting them and getting through the redirects |
You can find the full source code in the file spec2.js and the explanation in the video below.
Bonus: check the 404 resource
The crawl example has one additional test file 404-spec.js that shows how to verify the error page the site serves when you try to visit a non-existent URL. Again, we can use a combination of cy.request and cy.visit commands to verify the status code and the error page served. We do need to let the commands work on the status code 4xx by using failOnStatusCode: false option
1 | it('shows 404 error', () => { |
You can find the explanation in the video below
Happy Crawling 🕷