I love using slides.com to give my presentations, that's why you can see 150 of my public slide decks at slides.com/bahmutov. Lately I am experiencing a huge problem: when someone is asking me a question, or I need to explain a topic, often I know that I gave a presentation that has the right content. But how do I find it? How do I find the right slide?
It is becoming an issue, so let's see what we can do. I have used documentation scraping very successfully before, so I know if I can feed the text contents of the slide decks to Algolia for example, I could quickly find the answers. But unfortunately, Slides.com does not expose the API to grab the slide text and URLs directly. Thus I need to scrape my slide decks myself. Let's do this!
- The list of decks markup
- Getting slide elements from the test
- Use aliases
- Save deck information into a file
- Scraper the list periodically
- Discussion
🎁 You can find the source code for this blog post in the bahmutov/scrape-slides repository.
The list of decks markup
First, we need to grab the list of all my public decks from "slides.com/bahmutov". The list of decks has very nice CSS classes, and by inspecting and trying them in the DevTools console we can find the right one '.decks.visible .deck.public':
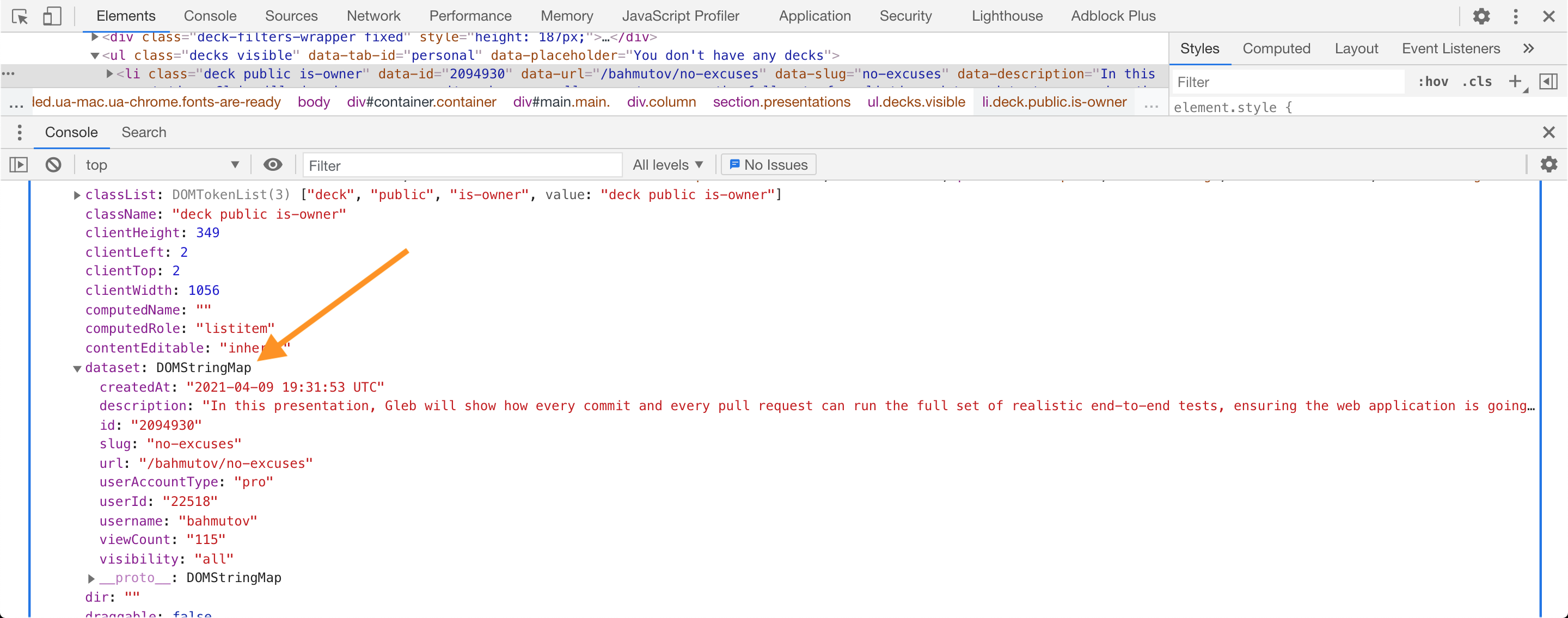
This selector returns 126 public decks. Can we grab the main properties of every deck from the DOM element, like the presentation's description, URL, etc? Yes! If you look at the properties of the DOM elements found, then you can locate the dataset property with everything I am interested in:
Getting slide elements from the test
Let's get the deck information using Cypress. Our configuration file is very bare-bones right now: we only use the baseUrl to directly visit the site
1 | { |
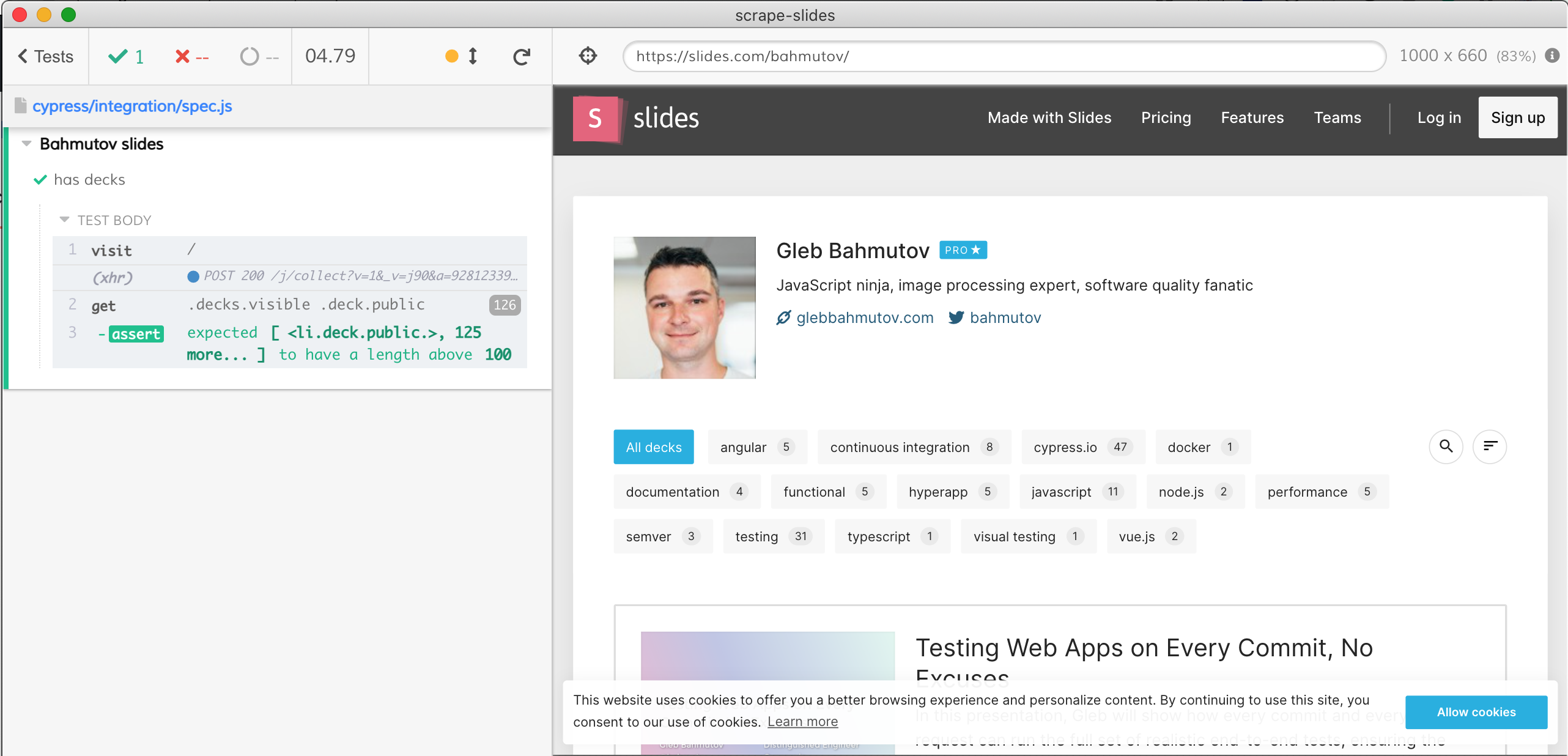
Our first test grabs the decks using the selector we found:
1 | /// <reference types="cypress" /> |
The test passes.
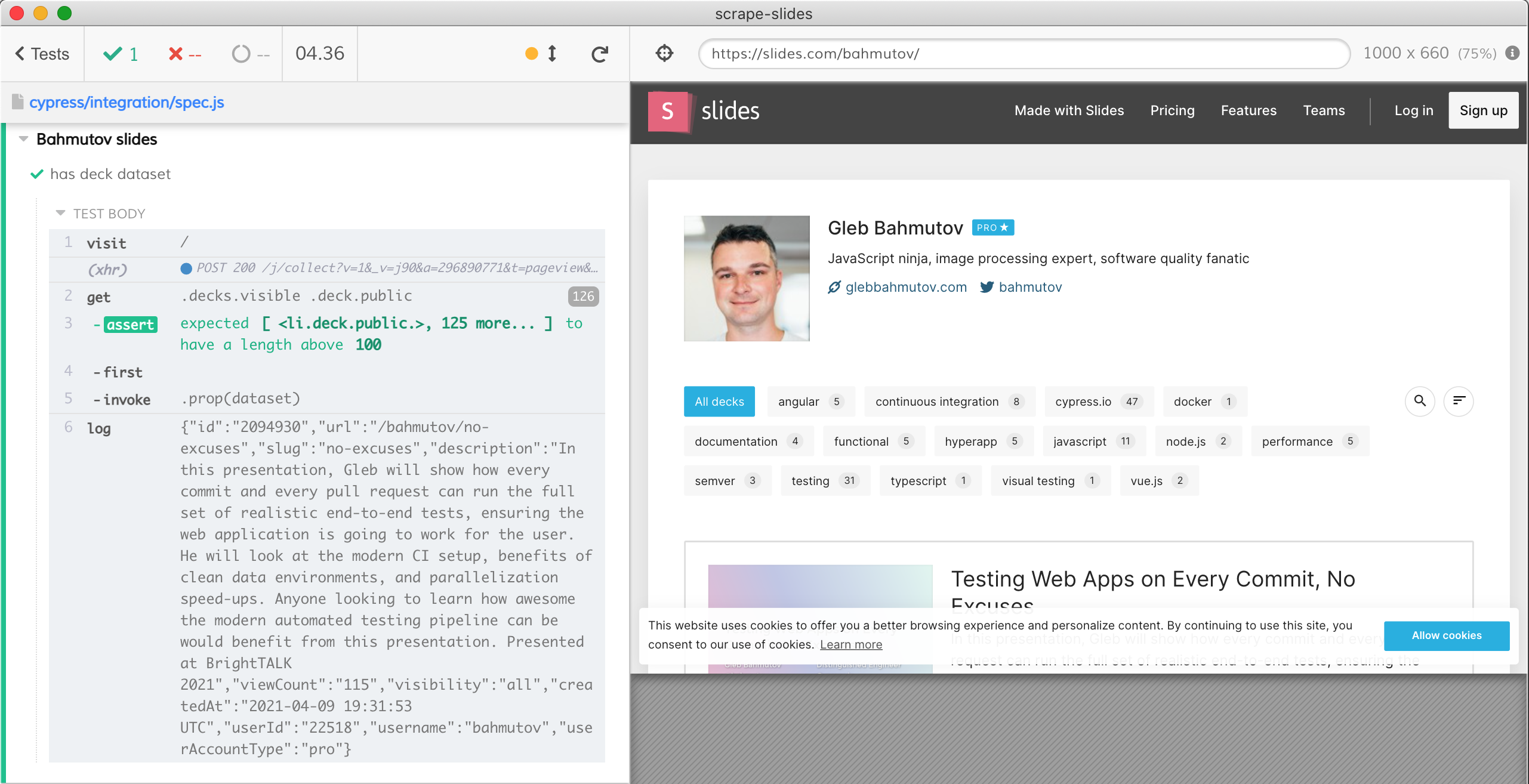
Can we get the dataset property, let's say from the first presentation? Yes, by invoking the prop method of the jQuery wrapper returned by the cy.get command. Let's run just the second test:
1 | /// <reference types="cypress" /> |
We are only interested in some properties from the dataset, let's pick them using the bundled Lodash library.
1 | /// <reference types="cypress" /> |
Beautiful.
Use aliases
Let's take a second to refactor our spec file. Every test needs the page, every test needs the list of presentation DOM elements. We can visit the page before each test, or even once using before hook and have all tests work after that:
1 | /// <reference types="cypress" /> |
Hmm, every test starts with getting the list of deck elements. Can we move the cy.get command to be with cy.visit and save the result into an alias?
1 | // 🔥 THIS WILL NOT WORK, JUST A DEMO |
Unfortunately the above code DOES NOT WORK because aliases are reset before each test, see the Variables and Aliases guide for details. Instead we can visit the page once, and then save the alias before each test by using both before and beforeEach hooks:
1 | describe('Bahmutov slides', () => { |
Save deck information into a file
Now let's grab the dataset property from each found deck element, and then save the result into a JSON file. I will omit the first two test we have already written, this is the test to write the file using cy.writeFile
1 | /// <reference types="cypress" /> |
Notice how we iterate over the DOM elements, saving the extracted and cleaned up dataset objects in an array to be saved later. The saved file decks.json can be found at the root of the project:
1 | [ |
Super.
Scraper the list periodically
Before we get into the presentation text search, we need to make sure we can run our list scraping operation periodically. Since our decks.json file can be checked into the source control, let's use GitHub Actions to run our Cypress tests - because the GH Actions have very nice access to the repo and push any changed files back to the repo, see my blog post Trying GitHub Actions for details.
1 | name: scrape |
Now every night the decks.json will be recreated - and if it changed, then the updated file will be pushed back into the repository.
Discussion
This is just the start, we are scraping the list of presentations as the first step to scraping each presentation's content. By using Cypress to scrape we can see what the algorithm does at each step. If something fails during scraping, we can inspect the screenshots and videos to determine what has changed. Follow this blog to read the future blog posts where we will look at each presentation and how to scrape its content.
For more information, see these blog posts and presentations
- presentation Test-Driven Documentation
- presentation Testing Your Documentation Search
- presentation Find Me If You Can
- blog post Scrape Static Site with Algolia
- blog post Search across my blog posts and github projects