In this blog post I try to see if using a modern database can be a good companion to Redux pattern. In particular I find that a database allows atomic data updates nicely by design. This blog post just shows the same example implemented using both the Redux library and then a similar pattern using RethinkDB database to manage the state.
You can find the companion source code at bahmutov/redux-vs-rethinkdb. If you want to jump ahead, see the code
Redux
Let us take a look at the latest craze in the MVC world - Redux. It keeps the entirety of your application's data in a single "store". There is no direct data manipulation outside the Redux flow, instead the data is mutated by pure functions that take the "state" from the "store" and additional arguments from "actions". The small example from the Redux home page shows this nicely
1 | import { createStore } from 'redux' |
We have a store, a state (really just a single variable), and we have a pure
function counter. This function counter takes the state and an action and returns new state,
which goes back into the store. Well, sometimes we just return the state - if we don't know
what to do for a particular action.
In majority of applications the state would be more than a single variable; it would be a complex (and hopefully immutable) object.
Let us inspect the function that updates the state in response to actions.
1 | function counter(state = 0, action) { |
This function counter(state, action) is called a reducer because multiple actions can be
added to plain a Array list and then reduced into the final state (see the section
"Introducing Actions and Reducers" in Full-Stack Redux Tutorial for a good example).
Every time the value inside the store changes, we can get an event, and print the current value for example.
1 | store.subscribe(() => |
To recap: we have a "store" and a function that produces the new "state" based on the input "action". We can also subscribe to store changes and do something with the new state (for example print it). All the data is stored in this "state" and the "store" controls the access to it.
Immutable data
In order to make Redux more powerful, people recommend using an immutable data object for the state. An immutable data object never changes any of its properties - instead it always creates a complete copy of itself but with a specific value modified. As the simple example, let us increment a person's age in a function. We are going to pass an object with "age" property
1 | var kid = { |
Notice that this is "immutable" modification by convention - the built-in JavaScript objects
are hard to make totally constant. Event the ES6 const keyword only makes the variable reference
constant, not the object it points to!
1 | const foo = { bar: 42 } |
Thus to prevent the accidental state object modification outside of the reducer function, we need a good library that freezes / modifies an object efficiently, preventing any direct access to its internal data. A popular choice is Immutable.js, which has a syntax slightly different from the plain JavaScript
1 | const kid = Immutable.Map({ |
With Immutable (or its equivalents), we are trying to ensure a consistent, performant and versatile application data container.
If this sounds familiar, well, remember the databases?
RethinkDB
Let us take a nice modern database, like RethinkDB. It can store all our data, can update a particular record, and even provide us with a change feed for a particular record.
We can easily create architecture similar to Redux, but having the state inside the Rethink database. I did not create a Redux-compatible store, instead I tried to recreate the way Redux store wraps around the state.
Let me create a sample table that would hold our data.
1 | function initDB() { |
We get into a different mind set right away: all database operations are asynchronous. We must use promises from the start (please, do not use callbacks, even if RethinkDB allows it). Promises have clear semantics, are part of the ES6 standard, and do not require inventing a new way of handling concurrency, unlike Redux Async Actions.
Initialize the database state
We now have an empty database table. Let us insert the default state object, and to keep
code parity with Redux example (somewhat), let us create the default state in the reducer
function counter and insert it into the database.
1 | // in Redux, default state was default parameter |
We will keep our application state in the table 'state' in the document with id: 1.
The JSON document just has the id and the initial value of 0 in the state property.
This code looks a lot more verbose than the simple Redux example. In reality, the state into the reducer would be a complex object, and modifying an Immutable state object would also require non-trivial code.
Also note that our function counter returns a promise resolved with the new rethinkState
object. Thus dispatching an action to the reducer function is an asynchronous operation.
From the main program, we can initialize the start state like this
1 | initDB() |
Or even shorter
1 | initDB() |
Always returning the state
One of the Redux tenets is the graceful handling of unknown actions by returning the input state unmodified. We can easily achieve this too.
1 | function counter(rethinkState, action) { |
Increment the state value
Let us implement a more interesting operation - increment the state variable
inside the RethinkDB using Redux pattern. We need to fetch the current value
and update it, but it has to be atomic - we cannot allow anyone else
to change the value between the fetch and update steps. Luckily, most databases
strive to implement the atomic updates (it is the "A" in
ACID properties). In RethinkDB, this is done
using ReQL update function.
1 | function counter(rethinkState, action) { |
We are getting the document with id 1 in rethinkState.table.get(1), then
add 1 to its property state and set the result back into state property
using state: rethinkState.r.row('state').add(1) expression.
We implement the "decrement" operation similarly, but using
r.row('state').add(-1) instead. The entire reducer function is verbose, but most of
the boilerplate could be factored out if necessary (I will show this later).
1 | function counter(rethinkState, action) { |
Starting the program we see the console messages
1 | setting the default state |
Why atomic updates matter
The two good Redux tutorials I read recently all show actions that update the local state AND send the update to the server. Here are the links
- Section "Calling All Servers" in Build a Better Angular 2 Application with Redux and ngrx
1 | updateItem(item: Item) { |
Notice that there is no synchronization or order control between updating and deleting an item. What happens if the user updates an item and then deletes it? What if the HTTP "delete" operation completes before HTTP "update" operation - will our store handle the inconsistent state? We will be trying to update an item that was already deleted, which could be problematic.
Similarly, in section "Sending Actions To The Server Using Redux Middleware" of Full-Stack Redux Tutorial we just send every action to the server via a socket.
1 | const socket = io(`${location.protocol}//${location.hostname}:8090`); |
In this case, we are using Socket.IO which uses TCP under the covers. The TCP
guarantees the delivery order, which is nice - at least the update; delete actions
will be delivered to the server in this order. Yet, we do not know if any other reducers
after the message is sent are reliable. Thus we can still get the problem where
something after the successful socker.emit takes a long time, allowing delete action
to execute completely AND then try to update non-existent record.
We can push this problem up or down our client code, use streams, merge actions to guarantee the store update order, etc. But this just means we are trying to solve the problem the database folks have already solved.
How do we use a database then to solve the application's sync between the client and the server? Just use the database wrapper, like rethinkdb-websocket-client. It will transparently work with central database, ensuring that you do not have to worry about inconsistent state on the client.
Subscribing to store changes
The Redux store allows anyone to subscribe to the state changes. RethinkDB has an equivalent, if not more powerful feature - change feeds.
Let us subscribe to the single document (the one with id 1) right after we create the database.
1 | initDB() |
The cursor returned from state.table.get(1).changes() has a callback cursor.each
that is executed every time there is a change. In our case, because we returned
the promise right after the database creation, we get a notification even for
the initial store creation!
1 | setting the default state |
Nice!
Stepping aside the example, the RethinkDB change feeds are very powerful because they allow very fine-grained subscriptions - an individual document, type of update, derived and aggregate feeds.
Removing the boilerplate
Let us simplify using the RethinkDB from the client's code. We need to recreate two API's similar to Redux example: first the store itself, and second the API to the state object passed to the reducer function.
"Redux" which is really RethinkDB
1 | // store creation abstraction |
Because we want to sync all promise-returning functions, we always schedule
actions by addition them to the existing queue Promise.
State object for reducer
Second, let us create a "state" object abstraction for reducer to use. It will hide
the actual RethinkDB calls from the reducer. This code goes inside the createStore
function.
1 | function createStore(reducer) { |
Our reducer function can use state.set and state.increment methods for much simpler
code
1 | function counter(state, action) { |
The client code now looks just like the Redux code, except under the hood the actions all go into the queue, because everything is asynchronous
1 | const store = createStore(counter) |
You can find the full example without boilerplate in src/rethink-no-boiler.js.
Bonus
RethinkDB is very developer friendly. For example, while running it exposes a nice admin interface, where I can view the currently held data. Here is the data after our little application has finished.
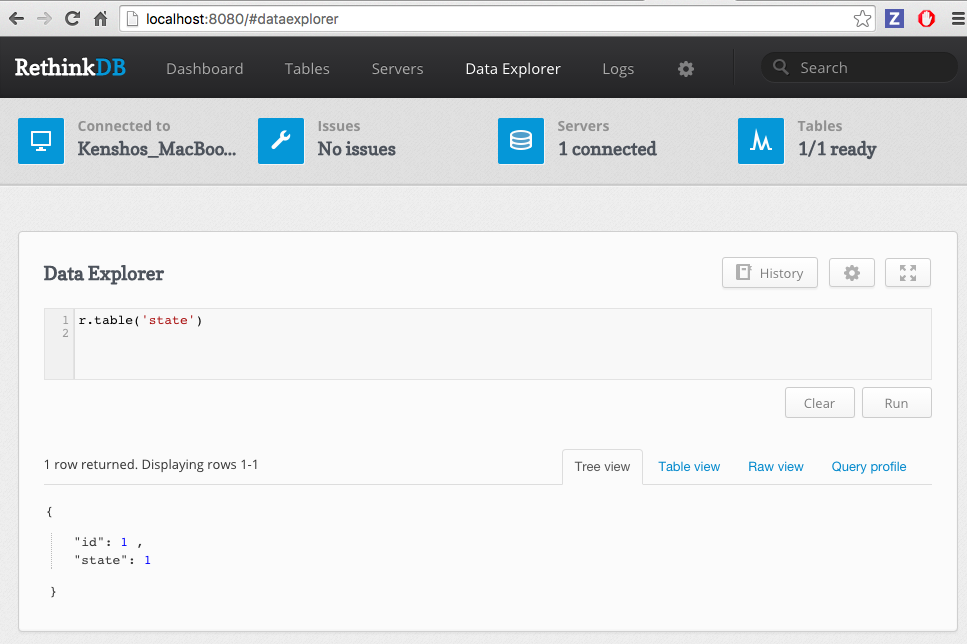
Notice the document { id: 1, state: 1 } showing the current application state.
Conclusions
I have written and rewritten this blog post several times. My thoughts circled around in a waltz before settling down on the idea of replacing the state with the database access.
Redux is more of a design pattern; an API to updating application's data, rather than a library or a component one must use. One has to think what makes sense to implement - a simple Redux store, a Redux store where each action is sent to the server for recording, or a store-like wrapper around local or remote database.
On a personal note, I deeply respect and admire the people behind both Redux library and RethinkDB. This blog post does not disparage or sings praises to any particular technology. Instead, I see a technology convergence, and maybe even rediscovery of an abstraction for dealing with application state from completely different perspectives.
Maybe a Redux store is a good interface to RethinkDB instead of Immutable data structure? Maybe an Immutable data structure then could be implemented on top of the database? Would it make sense for hybrid server and client case, similar to how Relay and GraphQL work? Maybe if every state update needs to be sent to the server, we are recreating the thick clients, or even mainframe architecture again?