Modern web applications suffer from a huge code and resource bloat. The page is downloading megabytes of stuff, while the screen stays blank for 10s of seconds - not a good experience! An alternative - a feather app, that comes in at less than 10KB minified and gzipped (25KB without gzip), certainly looks very very attractive. The app's author Henrik Joreteg built the application up from nothing - only adding the code when a feature was needed, without including the unnecessary parts.
I like Cycle.js - a honest reactive framework that is extremely powerful. Yet a simple program made with Cycle is quite large - it includes the Cycle framework itself (very small), virtual-dom and RxJs v4 as of this writing. All these libraries are very powerful, but their sizes add up.
I have created a simple example repo to go with this blog post at covered-cycle-example. You can see the application itself at glebbahmutov.com/covered-cycle-example
The dependencies and the program itself are minimal
1 | npm i -S @cycle/core @cycle/dom rx |
1 | const Cycle = require('@cycle/core') |
1 |
|
We are building a single "dist/app.js" bundle using webpack with the following configuration
1 | module.exports = { |
Let us build and try the program
1 | { |
1 | $ npm run build |
This Cycle application, unminified takes up 591KB of space. It works - we can open index.html and increment the counter using buttons.

You can find this code, including the built code inside dist/ using at the Git tag v1.0.0.
Minifying and zipping
We do not have to serve the produced JavaScript bundle of course - it is way too large, includes a lot of white space and comments. We should minify and compress it first. Unfortunately, the standard tool for this is uglifyjs2 that does not support ES6 fully yet. Thus I need to convert ES6 bundle code to ES5 first, then minify it. I will even mangle names for smaller bundle.
1 | { |
This produces the following files, each smaller than the last one
1 | $ ls -lh dist |
This is what we want to beat: 199KB minified and 50K gzipped bundles. We are going to do this by eliminating code portions that are truly unused in our small application.
Code coverage
Let us determine what parts of the application's code we are actually using when we run the example counter program. We cannot use the static analysis, like Rollup does during tree-shaking - every part of RxJs, and virtual-dom libraries is reachable from code. What we need is code coverage while we run the application to determine if there are parts of the built bundle that are never exercised!
I have done the code coverage for running web applications before using was-tested code coverage proxy. Let us add this proxy and instead of running the example application directly access it via the proxy.
1 | npm i -D http-server was-tested |
1 | { |
Instead of opening the example HTML page directly, we will serve it using simple static web
server. Then from a separate terminal we will start the code coverage proxy. The proxy will
instrument by default requests matching app.js$ pattern coming back from its target url.
Open url localhost:5050 which points at the was-tested proxy - you should see the application
running as before, except the code the browser receives is instrumented. The browser page now
sends the coverage report every 5 seconds (unless there were no changes). By just loading the
application we have covered about 40% of its statements inside dist/app.js! We can open the
coverage report in the HTML format to see the individual statements. The proxy is serving
the latest coverage report at localhost:5050/__report and it shows the following initial
coverage:
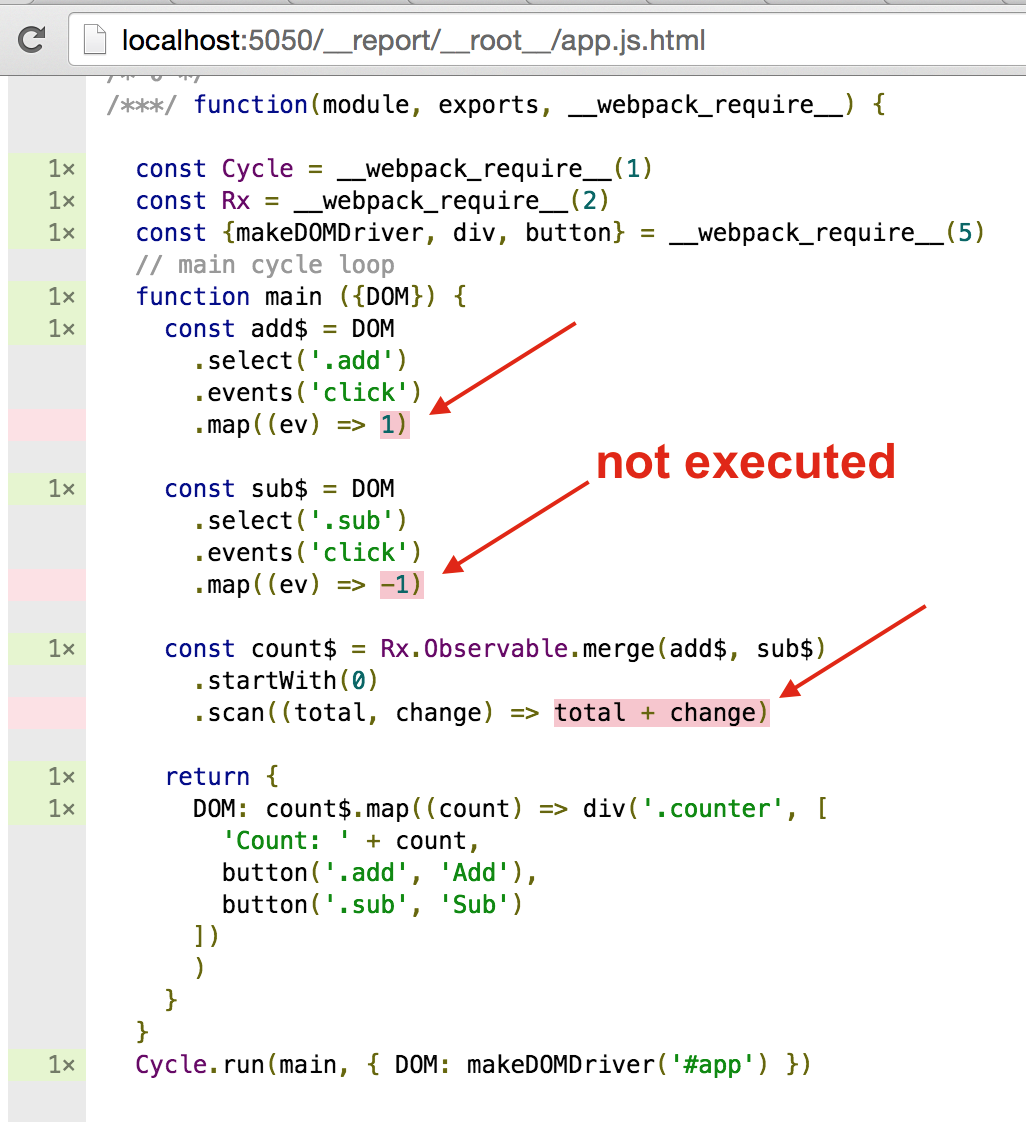
Note two important points:
- The code to setup the streams and start the processing is only executed once. That is why
we can use
constkeywords to declare every variable in the program. Only the data inside the streams will be changing when the program runs. - Some callback functions are not covered because they did not execute yet. For example, converting
from clickin "Add" event to "1" has NOT been executed yet, because the user has NOT clicked
the button yet! Similarly, the
scancallback has never executed, because there were no events in the merged stream.
If we click on "Add" and "Sub" buttons several times, the coverage will change.

Notice that the number of times scan callback (which functions as our "model update") was
executed is equal to the sum of number of times "add$" and "$sub" stream callbacks ran.
You can find the code at Git tag v1.1.0
Removing functions not covered
Let us take an extreme position on code coverage
Functions that were never executed during testing are not needed during runtime
If the code paths (and we operate not at the individual code statement level, but at function level) were never exercised, then we can "safely" remove them. Take a simple example that I placed in the folder shake-example
1 | function add (a, b) { |
The code only uses function add, thus we should remove sub to save space / shorten the
bootstrap time. Under Node, we can generate code coverage information quickly using
nyc instead of was-tested proxy.
1 | npm install -g nyc |
I picked functions as the smallest blocks of code, because removing individual code lines or branches might introduce completely unpredictable and hard to test behavior. Functions on the other hand (with at least single covered line inside) are safer to remove. Consider the example below. On the right the comment shows number of times a particular non-empty code line is executed.
1 | // number of times executed |
Every function declaration line is executed as soon as the function definition is processed.
The inside lines of a function are only executed if the function is called. Since the function
add is never called, the inside line return a + b has counter 0. Function abs shows the
dangers of removing lines from inside a function, even if the line is uncountered. We only
exercised the positive branch, removing the negative branch return -a would leave the function
in a very dangerous state.
Thus we will only remove the functions that are never called at all, even once.
Under the hood, nyc uses istanbul code coverage library,
same library as used by was-tested. Thus the output coverage file is the same. It has information
for each function: start location and if it was used or not. The functions are listed in order
found in the source file.
1 | { |
The above coverage file shows that the code inside the first function add was executed
at least once, while the second function sub was never called. To remove the uncovered function
from the code I wrote
fn-shake.js.
It loads the source code, parses it using esprima and then walks the
abstract syntax tree. For each found function declaration, it looks up the coverage flag.
If the function is NOT covered, it is removed from the tree.
1 | // only looks at the function start to match function |
The output tree is transformed back to the source code using
escodegen generator. For the above code.js example
we get the equivalent program
1 | function add(a, b) { |
You can find the code at Git tag v1.2.0
Minimal Cycle application
Let us apply the same "shaking" algorithm to the generated Cycle application bundle. Not every
function that was unused could be removed. For example, even if a function is not used,
we cannot remove add without removing all references to it.
1 | function add(a, b) { return a + b } |
If we just remove add we will get a reference error when trying to run the remaining code
1 | module.exports = add |
Thus I had to keep bunch of functions that were references in other places, especially more complex cases like this one
1 | function Item() {} |
While no one has used new Item anywhere in the bundle, we could not just remove the constructor
function as the removal was breaking assigning to the prototype.
Thus (initially) I had to keep a bunch of functions,
even though the entire code fragments were not used! Most of the code blocks not
removed came from RxJS library. Still the automated process has been able to remove about 270
unused functions, while the application still worked as before.
The application shrank by about 20% in the uncompressed source code, from 491KB to 414KB.
This was too small of a difference to matter in my opinion. Thus I implemented removing
adding properties to function prototypes that were unused. Basically, in the above example,
whenever I found assignment of the form <name>.prototype.<property> = ... I looked up
the function <name> - if the function itself was never used, then I eliminated all assignment
expressions, leaving only the function itself. I had to leave the function, because there were a
variety of situations where the function itself was used, and I did not want to track down
every occurrence like this one
1 | var Foo = (function () { |
In the future I could try shortening unused functions to just empty objects - then any reference to them would still be valid (functions are objects in JavaScript) and the bundle would still work.
Final result
Once the automatic coverage + elimination step finished (removing almost 600 functions from 2000), I got a bundle that was smaller. Running the same ES6 bundle -> ES5 bundle -> uglify2 -> gzip steps generated the following bundles.
1 | $ ls -lh dist |
Thus minified bundle went down from 199KB to 141KB (29% decrease) and the gzipped file went down from 50KB to 38KB (24% decrease).
What is more important is the initial bootstrap time. Once a bundle is downloaded, the browser has to evaluate the JavaScript. We can cache the bundle in the browser to avoid downloading penalty, but we cannot short circuit the evaluation time - the only way to start the code execution faster is to evaluate less code!
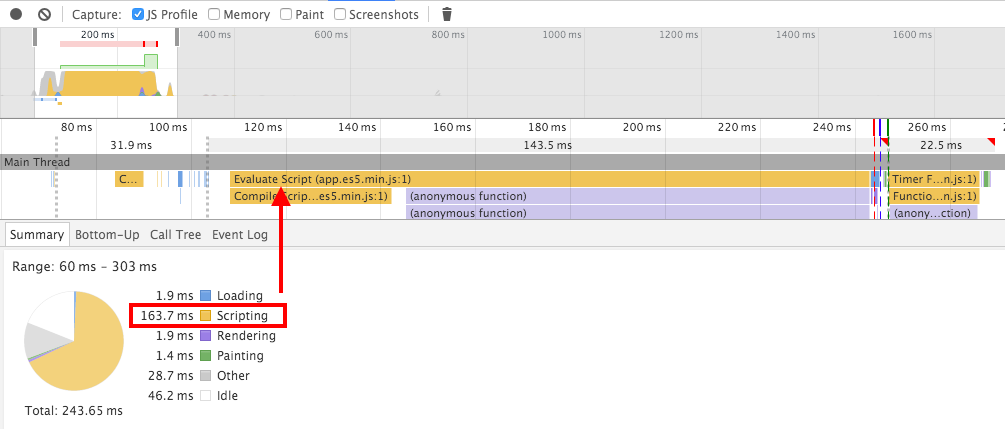
Here is the browser JavaScript profile for the original bundle - it takes 160ms to evaluate the bundle.
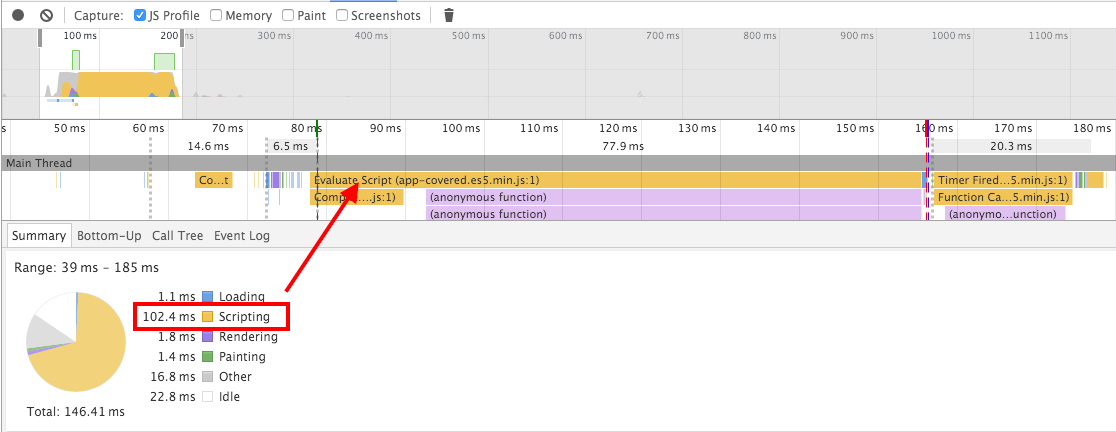
The smaller bundle has the corresponding shorter evaluation period - only 100ms.
Smaller file, shorter download time and faster application startup time - what not to love?
I feel there is still room for improvement, especially in completely removing any unused prototype functions. I also believe that new tree-shaking approach possible with ES6 code analysis will be very very beneficial once all the libraries used in this experiment support ES6.