I have been using continuous builds for many years. My favorite in-house tool is Jenkings, my favorite CI build as a service is travis-ci. I also have been using source code coverage tools during unit tests, and have been publishing results on coveralls.io. Recently I tried static source (JavaScript) analysis as a service at codacy.com and codeclimate.com.
I liked both static source analysis websites, they worked completely automatically with our github project. The results (and project badges) give me and my users a peace of mind. Software quality (and lack of it), was always an interest of mine, I and started thinking:
If I had to design static source analysis as a service offer, what would it do?
Pick right industry name
I prefer using more generic "Code Quality as a Service (CQaaS)", rather than static source analysis as a service. This seems to be the current trend, according to this DZone article. We want to measure quality rather than static code properties. For example, complex code that is well tested has higher quality than simple code without any tests.
Assume Git and CI
I would assume that projects that enable code quality analysis use Git for source
control and have continuous build setup. I would make code analysis a step in the CI
build script (for example in .travis.yml file using after_success: step).
Require unit tests and code coverage info
I seriously doubt that a good project is possible without unit tests. I also think that a lot of information can be derived from comparing code coverage and complexity information. This is why I designed risk-map - a treemap source code visualization that ties source file metrics (line of code, cyclomatic, any Halstead metric) and code coverage information. The treemap is good for visualizing source file tree properties since it groups files in the same folder next to each other; a much more meaningful grouping than listing files alphabetically.

If you need JavaScript unit tests, pick a right test framework and start testing as soon as possible.
If you need JavaScript code coverage:
- For browser code, use Karma with karma-coverage plugin.
- For unit tests under Node, especially QUnit tests, use gt. gt can even run simple BDD (aka Jasmine, Mocha) unit tests.
If you need to collect code complexity metrics, there are several tools
- Stand alone js-complexity-viz
- As grunt plugin grunt-complexity
- Plato generates beautiful reports.
I would design my service to take in generated reports, and not even try computing this information myself. Mainly because these tools run quickly, produce output useful to the developer and should be part of the default build pipeline. coveralls.io uses this approach - they only injest line coverage information and source code, but do not try to compute it themselves.
Concentrate on tools that do NOT run quickly
I would detect code duplicate in the source code. This static analysis is time-consuming, especially in large code bases. Yet this is very useful service to prevent code bloat and cut down on the number of tests necessary.
I would detect number of public functions / methods / variables. Code that is simpler to reuse tries to hide details, and only export small number of variables. Static analysis tools that detect all the global variables and coupling among modules is slow to run - a great candidate for a service, rather than standard build.
Analyze change
A service that looks at the history of the source code can give interesting insights into how code evolves
Is the code quality increasing or suddenly dropping? Who among the developers contributed the most to code refactoring and increased code coverage? Some people even made it into a game / competition.
scrutinizer-ci does nice job showing previous grade, change direction and new grade. See screenshots.
Can we tie together low code complexity, low number of exposed functions, high unit test coverage with number of bugs? If my service could integrate with bug tracking service, I could see which files were modified in response to a bug, then predict where bugs would happen. My hunch is that bugs occur in high complexity, low test coverage files with high churn with recent changes by a developer who has not touched this code before. Code quality service could actually prove this!
Work with existing tools
I use several tools to tighten static code in my projects: linters, complexity metrics, etc (read about them in "Tightening project"). Almost all these tools run as grunt or gulp plugins. Thus I would make my code quality service use the existing task settings
Instead of manually configuring which source files to analyze, and which to exclude, the tool could look inside the Gruntfile.js (if it exists) and grab jshint file wild cards.
Support other (non source code) tools, for example grunt-filenames and grunt-todos collect secondary information from the source code, yet provide great insight into code uniformity and remaining technical debt.
Generate prioritized actionable task list
I have when a tool dumps 100s of errors and warnings on me. Instead I want a service to:
Show me the top 5 most urgent issues, hiding the rest below the fold. The top issue should have the context information (like the source) right away. It should also explain why it is the most urgent one.
I should be able to see the author responsible for each issue (as determined from the version history). By integrating with issue tracker, I should be able to click one button and generate a detailed TODO issue. I should be able to assign the new issue either to the person responsible for the original code, or to anyone else. Of course the issue should not be creatable if I already have done it once. Instead my service should show the issue already created.
Sentry has good UI with prioritized issue list I like. There is even Sentry-JIRA integration plugin that makes creating new issue from crash reports a breeze.
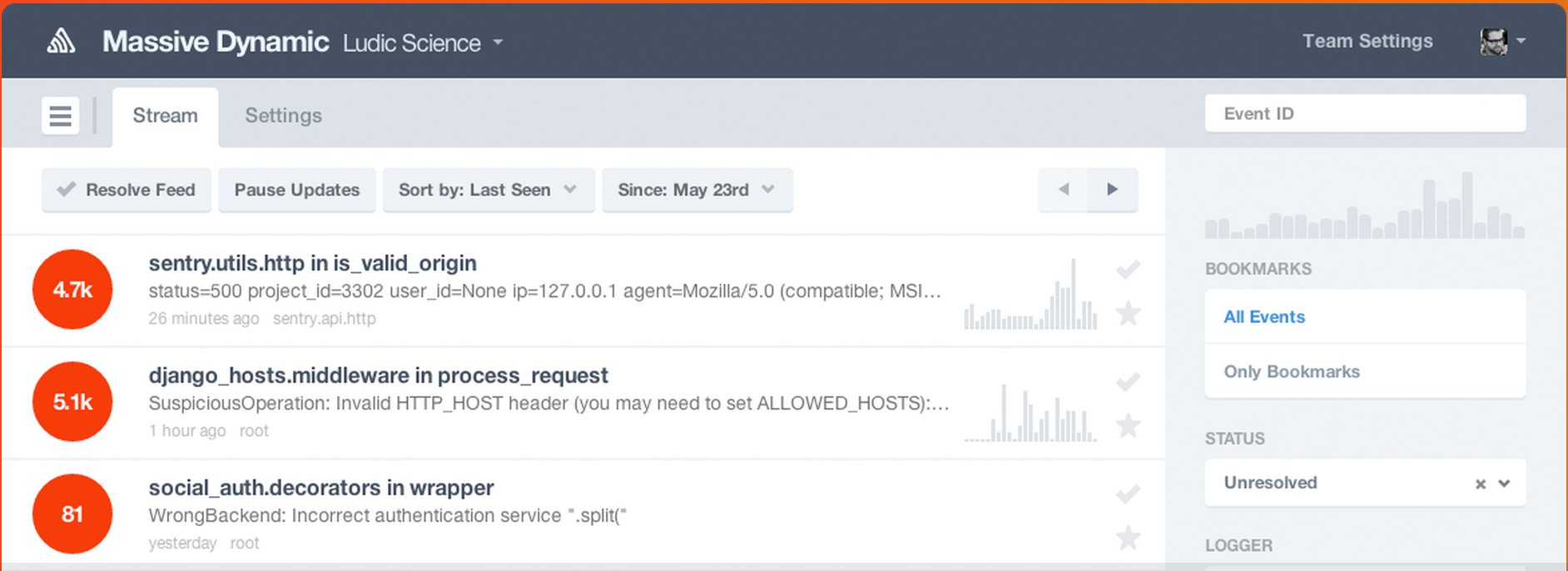
Show goals
Linting and unit testing should run on the local dev box, and should be quick enough to while I am developing. The tight lint - build - test loop makes sure I catch problems before committing code. The central continuous build server performs the same actions just to make sure we can build from clean state, and there are no merge problems.
If we can lint source code locally, why would I need a separate code quality as a service?
When I run lint locally, or when CI runs linter, it is a binary action. It either passes or not. If we setup lint to generate warnings instead of errors, the warnings just get ignored, in my experience. So the current lint settings only are as strict as possible without making the build fail.
If I want to tighten lint settings, I can at least check how many lint settings are specified
in my rule set, for example using jshint-solid.
If my .jshintrc file only specifies 10% of all possible jshint rules,
- how much effort would it take to enable all rules?
- how strict are my current rules?
This is where a separate quality as a service becomes useful. Instead of just passing the linter over the code (binary pass / fail result), it can tighten the rules, run linter, and collect the results. Then the service can report how many warnings / errors are there if we bumped the rules' strictness to various degrees from loose all the way to the most strict ruleset.
For example, we can start with basic .jshintrc that only specifies basic settings,
just like grunt-contrib-jshint
project does
1 | { |
According to jshint-solid this rule set only covers 18% of all possible jshint settings. Some settings
are also not the stricted possible, for example sub allows using [] notation for property access,
when it is possible to express using dot notation.
How many warnings would we have to fix if we turned on 50% of all rules? What if this 50% where all set to the stricted level? There is no tool currently that gives an answer. Thus it is hard to plan code quality improvements (linting is the first step towards more uniform code and catching some simple errors by static analysis) during sprint planning. If we had this information, we could include this as a very straight forward task during agile sprint planning.
Instead of single grade, show progress towards levels
To better show the roadmap to code quality improvement, I propose to show progress towards quality level. A good visual system in my mind shows level and progress towards fulfilling this level at 100%. Here is how levels could map to rule sets and badges.
 -
the project only specified some lint settings (25% of them) and recently fulfilled them.
The red background color maps nicely to the project being at the basic level of code quality.
The up arrow means the project has recently improved by fixing some issues or passing at higer
/ stricter settings.
-
the project only specified some lint settings (25% of them) and recently fulfilled them.
The red background color maps nicely to the project being at the basic level of code quality.
The up arrow means the project has recently improved by fixing some issues or passing at higer
/ stricter settings. -
project is passing below 50% of settings but above 25%.
-
project is passing below 50% of settings but above 25%. -
reliable projects specify < 75% of settings and at pretty strict level too. The down arrows
shows that the project has recently generated new warnings, lowering its quality.
-
reliable projects specify < 75% of settings and at pretty strict level too. The down arrows
shows that the project has recently generated new warnings, lowering its quality. -
almost all settings are listed, neither major rules are omitted, nor they are set to be loose.
-
almost all settings are listed, neither major rules are omitted, nor they are set to be loose.
For each level, the project dashboard should show a prioritized list of issues to be addressed
before next level can achieved. Maybe even with git blame used to determine who is responsible
for the code to be modified to fix the identified issues.
These levels could be combination of jshint, eslint, jscs and other tools I described (TODOs, code coverage vs complexity metrics, etc).
Conclusion
Currently we have a wide variety of continuous build services, and static code analysis services have just started to show up. Opening a code quality specifically targeted at JavaScript language would influence the most exciting platform today. The command line tools for analysis are already available. One just needs to use them and make a useful 3rd party service.